可伸缩 Web 架构与分布式系统
服务
当考虑可伸缩系统的设计时,(服务)有助于各功能去耦并且通过一个清晰定义的接口思考系统的每个部分。在实践中,这种方式的系统设计表明其拥有一个面向服务的架构(SOA)。对于这些类型的系统,每个服务都有它们各自确切的功能上下文,并且和该上下文以外的任何交互均是与一个抽象的接口进行的,特别是另一个服务的公有接口。
将一个系统拆解为一个互补的服务集合解耦了那些相互间的操作。这种抽象有助于建立服务间明确的关系、潜在的(运行)环境、服务的消费者。通过这些清晰的描绘有助于隔离问题,并且允许每个部分能够相互独立地进行扩展。这种面向服务的系统设计有点类似与面向对象编程。
在我们的例子中,所有上传和获取图片的请求都是在同一服务器上处理,但是,如果系统想要达到可伸缩,那么将这两个功能拆分成各自的服务是非常明智的。
快进下,假设这些服务被大量使用;这样的场景将非常易于看到更久(原文此处是how longer writes will impact the time it takes to read the images)的写操作会如何影响(系统)读取图片的时间(因为这两个功能会竞争共享资源)。在这样的架构下,这种影响是真实存在的。即使上传和下载速度是一样的(对于大多数IP网络来说不一定是,因为大多数都是设计成下载速度与上传速度3:1的比例),文件通常直接从缓存中读取,而写入则最终必须到达磁盘(在最终一致的场景中可能会被写入多次)。即使所有东西都是从内存或者磁盘(比如SSD固态硬盘)读取,数据库的写入操作总还是比读取要慢(Pole Position, 一个开源的数据库评测工具)。
另一个潜在的设计问题是,一个像Apache或者lighttpd的web服务器,通常有一个它可以维持并发连接数的上线(默认大约在500左右,但可以调得更高),并且在高流量下,写操作将很快消耗完所有(连接资源)。由于读操作可以异步进行,或者利用其它性能调优如gzip压缩或者chunked transfer encoding,web服务器可以转换为更快服务读操作、更快切换客户端,从而比最大连接数每秒服务更多的请求(Apache最大连接数设置为500,但一般都能每秒服务数千个请求)。写操作,在另一方面,倾向于在上传过程中维护一个打开状态的连接,所有上传一个1M大小的文件在大多数家庭网络上将花费超过1秒的视角,所以web服务器只能同时处理500个写操作。
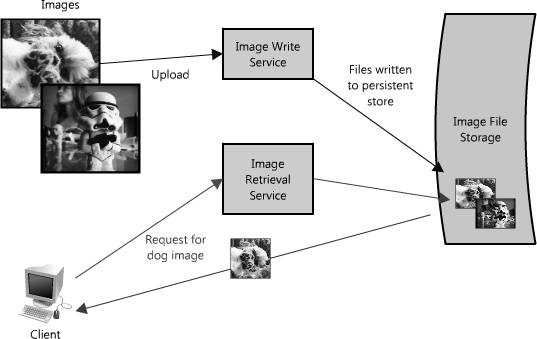
图 1.2: 读写分离
将图片的读、写操作拆分成各自的服务是一个应对这种瓶颈很好的解决方案,如图1.2。这样允许我们能够独立的扩展它们(我们通常会读大于写),而且有助于将每一点的进展情况看得更加清晰。最后,这样可以分离未来的担心,可以更简单地解决像读操作缓慢的问题,并做到可伸缩。
这种方法的好处在于我们能够独立(不影响其他)解决问题——我们不用担心在同一上下文中写入、读取新的图片。这两者(服务)仍然影响着全部的图片,但均能通过service-appropriate方法优化它们的性能(比如让请求排队,或者缓存受欢迎的图片——更多种方式请见下文)。从一个维护和成本的视角出发,每个服务均能独立、按需伸缩是非常好的,因为如果它们被组合、混合在一起,在上面讨论的场景下,可能某一(服务)不经意间就会影响到其他(服务)的性能。
当然,当你考虑着两个不同点时,上面的例子能够工作得很好(事实上,这跟一些云存储提供商的实现方案和CDN很类似)。尽管还有很多方法来处理这些类型的瓶颈,但每个都有不同方面的权衡。
例如,Flickr通过将用户分布在不同区域的方法来解决读/写问题,比如每个分区只处理一定数量的用户,随着用户的增加,集群会更多的分区(参考Flickr可伸缩报告)。在第一个例子中,基于实际使用(整个系统的读写操作数量)可以更容易地伸缩硬件,然而Flickr是基于它的用户(但强制假设用户的使用率均等,所以仍有额外的容量)。对于前者来说,停电或者一个服务的问题就会降低整个系统的功能性(比如没人可以写入文件),然而Flickr的一个分区停电仅会影响到这个分区相应的用户。第一个例子易于操作整个数据集,比如升级写入服务来包含新的元数据或者搜索所有的图片元数据,然而在Flickr的架构下,每个分区均需要被更新或搜索(或者一个搜索服务需要能够整理相关元数据——事实上他们确实这么做)。
对于这些系统来说没有孰对孰错,而是帮助我们回到本章开头所说的准则,判断系统需求(读多还是写多还是两者都多,并发程度,跨数据集查询,搜索,排序等),检测不同的取舍,理解系统为什么会失败并且有可靠的计划来应对失败的发生。


