首页
培训课程
Java全端工程师
前端+鸿蒙多端开发工程师
大数据AI智慧工程师
嵌入式物联网
鸿蒙应用开发
名师团队
免费资源
视频教程
配套工具
教程资料
关于尚硅谷
报名流程
全国中心
北京
上海
深圳
武汉
西安
成都
首页
/
技术聚焦
尚硅谷大数据技术之Hadoop(MapReduce)(新)第2章 Hadoop序列化
发布日期:2018-10-23
作者:atguigu
1523人浏览
3.
3 S
huffle机制
3
.3.1 S
huffle机制
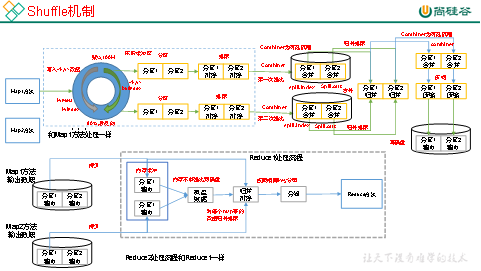
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。如图4-14所示。
图4-14 Shuffle机制
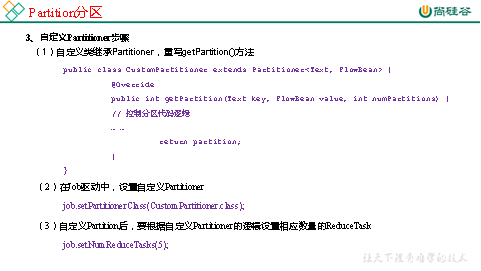
3.3.2 Partition
分区
上一篇:
尚硅谷大数据技术之Hadoop(HDFS)第6章 DataNode(面试开发重点)
下一篇:
1024程序员节:尚硅谷“关爱珍稀程序猿活动”惊艳IT圈
最新资讯
Java 中的面向对象编程:封装、继承、多态、抽象
Java 中的 HashMap
Java中的PriorityQueue
Java Switch 案例讲解
Java(JVM)内存模型
Java集中处理字符串工具函数
Java中的插入排序:一种简单且高效的算法
在Java中将双精度值转换为字符串并显示
热门视频
更多>