尚硅谷大数据技术之电信客服
3.3 数据分析
我们的数据已经完整的采集到了HBase集群中,这次我们需要对采集到的数据进行分析,统计出我们想要的结果。注意,在分析的过程中,我们不一定会采取一个业务指标对应一个mapreduce-job的方式,如果情景允许,我们会采取一个mapreduce分析多个业务指标的方式来进行任务。具体何时采用哪种方式,我们后续会详细探讨。
分析模块流程如图3所示: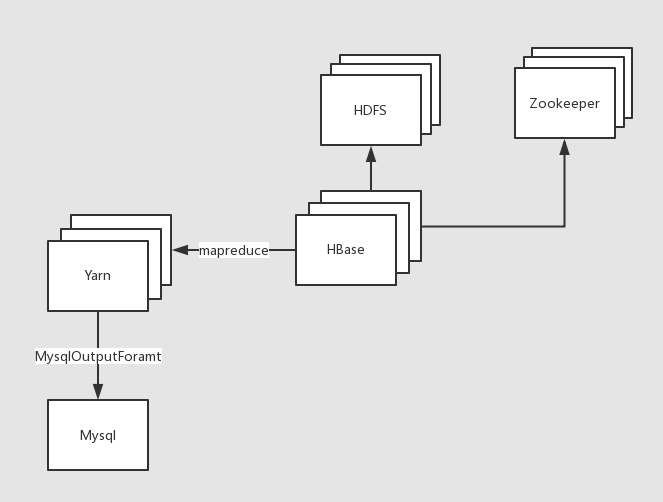
图3 分析模块流程图
业务指标:
- a) 用户每天主叫通话个数统计,通话时间统计。
- b) 用户每月通话记录统计,通话时间统计。
- c) 用户之间亲密关系统计。(通话次数与通话时间体现用户亲密关系)
3.3.1 需求分析
根据需求目标,设计出下述(3.2.2)表结构。我们需要按照时间范围(年月日),结合MapReduce统计出所属时间范围内所有手机号码的通话次数总和以及通话时长总和。
思路:
- a) 维度,即某个角度,某个视角,按照时间维度来统计通话,比如我想统计2017年所有月份所有日子的通话记录,那这个维度我们大概可以表述为2017年*月*日
- b) 通过Mapper将数据按照不同维度聚合给Reducer
- c)通过Reducer拿到按照各个维度聚合过来的数据,进行汇总,输出
- d) 根据业务需求,将Reducer的输出通过Outputformat把数据
数据输入:HBase
数据输出:Mysql
HBase中数据源结构:
表6
|
标签 |
举例&说明 |
|
rowkey |
hashregion_call1_datetime_call2_flag_duration 01_15837312345_20170527081033_13766889900_1_0180 |
|
family |
f1列族:存放主叫信息 f2列族:存放被叫信息 |
|
call1 |
第一个手机号码 |
|
call2 |
第二个手机号码 |
|
date_time |
通话建立的时间,例如:20171017081520 |
|
date_time_ts |
date_time对应的时间戳形式 |
|
duration |
通话时长(单位:秒) |
|
flag |
标记call1是主叫还是被叫(call1的身份与call2的身份互斥) |
- a) 已知目标,那么需要结合目标思考已有数据是否能够支撑目标实现;
- b) 根据目标数据结构,构建Mysql表结构,建表;
- c) 思考代码需要涉及到哪些功能模块,建立不同功能模块对应的包结构。
- d) 描述数据,一定是基于某个维度(视角)的,所以构建维度类。比如按照“年”与“手机号码”的组合作为key聚合所有的数据,便可以统计这个手机号码,这一年的相关结果。
- e) 自定义OutputFormat用于对接Mysql,使数据输出。
- f) 创建相关工具类。


