Cube构建优化_大数据培训技术
Cube构建优化
从之前章节的介绍可以知道,在没有采取任何优化措施的情况下,Kylin会对每一种维度的组合进行预计算,每种维度的组合的预计算结果被称为Cuboid。假设有4个维度,我们最终会有24 =16个Cuboid需要计算。
但在现实情况中,用户的维度数量一般远远大于4个。假设用户有10 个维度,那么没有经过任何优化的Cube就会存在210 =1024个Cuboid;而如果用户有20个维度,那么Cube中总共会存在220 =1048576个Cuboid。虽然每个Cuboid的大小存在很大的差异,但是单单想到Cuboid的数量就足以让人想象到这样的Cube对构建引擎、存储引擎来说压力有多么巨大。因此,在构建维度数量较多的Cube时,尤其要注意Cube的剪枝优化(即减少Cuboid的生成)。
1 找到问题Cube
1.1 检查Cuboid数量
Apache Kylin提供了一个简单的工具,供用户检查Cube中哪些Cuboid 最终被预计算了,我们称其为被物化(Materialized)的Cuboid。同时,这种方法还能给出每个Cuboid所占空间的估计值。由于该工具需要在对数据进行一定阶段的处理之后才能估算Cuboid的大小,因此一般来说只能在Cube构建完毕之后再使用该工具。目前关于这一点也是该工具的一大不足,由于同一个Cube的不同Segment之间仅是输入数据不同,模型信息和优化策略都是共享的,所以不同Segment中哪些Cuboid被物化哪些没有被物化都是一样的。因此只要Cube中至少有一个Segment,那么就能使用如下的命令行工具去检查这个Cube中的Cuboid状态:
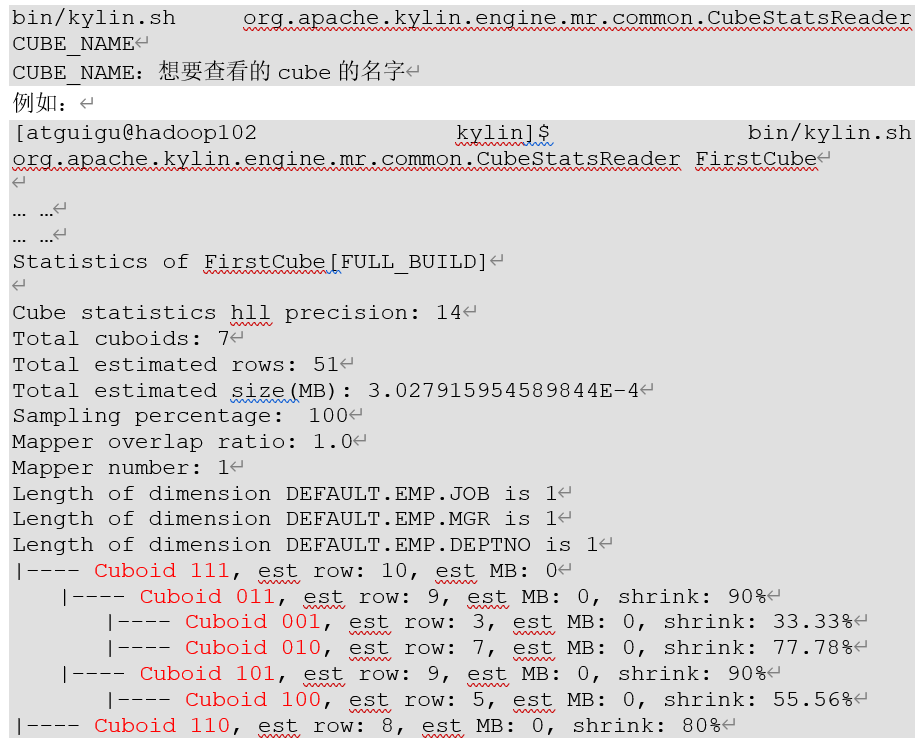
从分析结果的下半部分可以看到,所有的Cuboid及它的分析结果都以树状的形式打印了出来。在这棵树中,每个节点代表一个Cuboid,每个Cuboid都由一连串1或0的数字组成,如果数字为0,则代表这个Cuboid中不存在相应的维度;如果数字为1,则代表这个Cuboid中存在相应的维度。除了最顶端的Cuboid之外,每个Cuboid都有一个父亲Cuboid,且都比父亲Cuboid少了一个“1”。其意义是这个Cuboid就是由它的父亲节点减少一个维度聚合而来的(上卷)。最顶端的Cuboid称为Base Cuboid,它直接由源数据计算而来。
每行Cuboid的输出中除了0和1的数字串以外,后面还有每个Cuboid 的的行数与父亲节点的对比(Shrink值)。所有Cuboid行数的估计值之和应该等于Segment的行数估计值,每个Cuboid都是在它的父亲节点的基础上进一步聚合而成的,因此从理论上说每个Cuboid无论是行数还是大小都应该小于它的父亲。在这棵树中,我们可以观察每个节点的Shrink值,如果该值接近100%,则说明这个Cuboid虽然比它的父亲Cuboid少了一个维度,但是并没有比它的父亲Cuboid少很多行数据。换而言之,即使没有这个Cuboid, 我们在查询时使用它的父亲Cuboid,也不会有太大的代价。那么我们就可以对这个Cuboid进行剪枝操作。


