可伸缩 Web 架构与分布式系统
分区
单台服务器可能没法放下海量数据集。也可能是一个操作需要太多计算资源,消耗性能,使得有必要增加(系统)容量。无论是哪种情况,你都有两种选择:垂直扩展(scale vertically)或者水平扩展(scale horizontally)。
垂直扩展意味着在单台服务器上增加更多的资源。所以对于大数据来说,这意味着增加更多(更大容量)的硬盘以便让单台服务器能够容纳整个数据集。对于计算操作的场景,这意味着将计算任务交给一台拥有更快CPU或者更多内存的大型服务器。对于每种场景,垂直扩展是通过自身(个体)能够处理更多的方式来达到目标的。
另一方面,对于水平扩展来说,就是增加更多的节点。对于大数据集,可能是用另一台服务器来存储部分数据集;而对于计算资源来说,则意味着将操作进行分解或者加载在一些额外的节点上。为了充分利用水平扩展的优势,这(译者认为此处指代的是系统支持水平扩展。垂直扩展对于应用来说无需修改,通常升级机器即可达到目的。而水平扩展就要求应用架构能够支持这种方式的扩展,因为数据、服务都是分布式的,需要从软件层面来支持这一特性,从而做到数据、服务的水平可扩展。)应该被天然地包含在系统架构设计准则里,否则想要通过修改、隔离上下文来达到这一点将会相当麻烦。
对于水平扩展来说,通常方法之一就是将你的服务打散、分区。分区可以是分布式的,这样每个逻辑功能集都是分离的;分区可通过地理边界来划分,或者其他标准如付费/未付费用户。这些设计的好处在于它们能够使得服务或数据存储易于增加容量。
在我们的图片服务器例子中,可以将单台存储图片的服务器替换为多台文件服务器,每台保存各自单独的图片集。(见图1.4)这样的架构使得系统能够往各台文件服务器中存入图片,当磁盘快满时再增加额外的服务器。这种设计将需要一种命名机制,将图片的文件名与所在服务器关联起来。一个图片的名字可以通过服务器间一致性Hash机制来生成。或者另一种选择是,可以分配给每张图片一个增量ID,当一个客户端请求一张图片时,图片检索服务只需要维护每台服务器对应的ID区间即可(类似索引)。
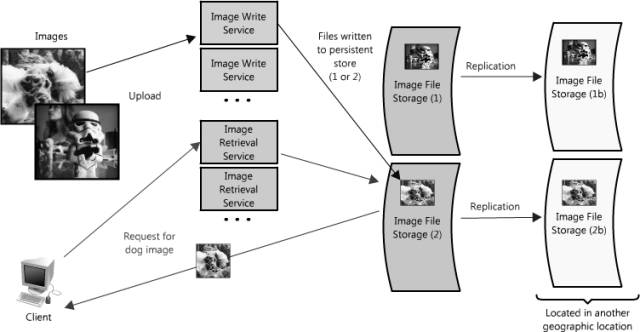
图1.4:图片托管应用,加入冗余和分区特性
当然,将数据或功能分布在多台服务器上会带来很多挑战。关键问题之一是数据局部性(data locality);在分布式系统里,数据离操作或者计算点越近,系统性能就越高。因此将数据分布在多台服务器可能是有问题的,任何需要(数据)的时候都可能不在本地,使得服务器必须通过网络来获取所需的信息。
另一个潜在问题是不一致性。当不同的服务在对同一块共享资源进行读、写时,可能是另一个服务或者数据,就会存在竞争条件的机会——当一些数据将被更新,但读操作先于更新发生——这类场景下数据就会发生不一致。例如,在图片托管这个场景下,竞争条件会发生在一个客户端发出将小狗图片标题由“Dog”更新为“Gizmo”的请求,但同时另一个客户端正在读取该图片这样的情况下。在这样的情况下,第二个客户端就不清楚接收到的标题会是“Dog”还是“Gizmo”。(此端译者并不理解作者原意,因为无论是在分布式还是在单机环境下,都可能出现同时读、写的操作,返回结果取决于底层存储对同时接收到的请求处理的调度,可能读先于写,反之亦然,故此处的例子用来解释不一致是否并不恰当?)
诚然,关于数据分区还存在很多阻碍,但分区通过数据、负载、用户使用模式等使得每个问题分解成易处理的部分。这样有助于可伸缩性和可管理型,但也不是没有风险的。有很多方法能够用来降低风险、处理失败问题;但为了简化篇幅,本章就不覆盖(这些方法)了。如果你有兴趣想了解更多,可以看下我博客上发表的关于容错性和监控的相关文章。


