(新)尚硅谷大数据技术之Hadoop(入门)第4章 Hadoop运行模式
4.3.6 群起集群
- 1. 配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[atguigu@hadoop102 hadoop]$ vi slaves
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[atguigu@hadoop102 hadoop]$ xsync slaves
- 启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)启动HDFS
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[atguigu@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[atguigu@hadoop104 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
(3)启动YARN
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop104:50090/status.html
(b)查看SecondaryNameNode信息,如图2-41所示。
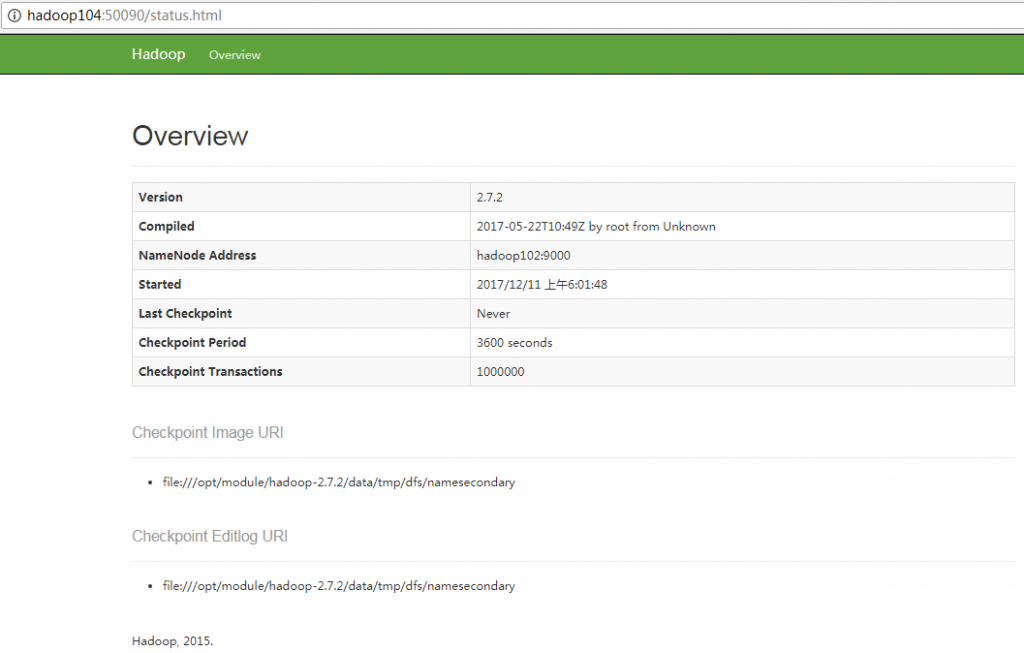
图2-41 SecondaryNameNode的Web端
- 集群基本测试
(1)上传文件到集群
上传小文件
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/atguigu/input
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -put wcinput/wc.input /user/atguigu/input
上传大文件
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -put
/opt/software/hadoop-2.7.2.tar.gz /user/atguigu/input
(2)上传文件后查看文件存放在什么位置
(a)查看HDFS文件存储路径
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.10.107-1495462844069/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盘存储文件内容
[atguigu@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
atguigu
atguigu
(3)拼接
-rw-rw-r--. 1 atguigu atguigu 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 atguigu atguigu 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 atguigu atguigu 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 atguigu atguigu 495635 5月 23 16:01 blk_1073741837_1013.meta
[atguigu@hadoop102 subdir0]$ cat blk_1073741836>>tmp.file
[atguigu@hadoop102 subdir0]$ cat blk_1073741837>>tmp.file
[atguigu@hadoop102 subdir0]$ tar -zxvf tmp.file
(4)下载
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -get
/user/atguigu/input/hadoop-2.7.2.tar.gz ./
4.3.7 集群启动/停止方式总结
- 1. 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
- 2. 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh


