揭秘Flink四种执行图(上)——StreamGraph和JobGraph
Flink的Task任务调度执行
1、Graph的概念
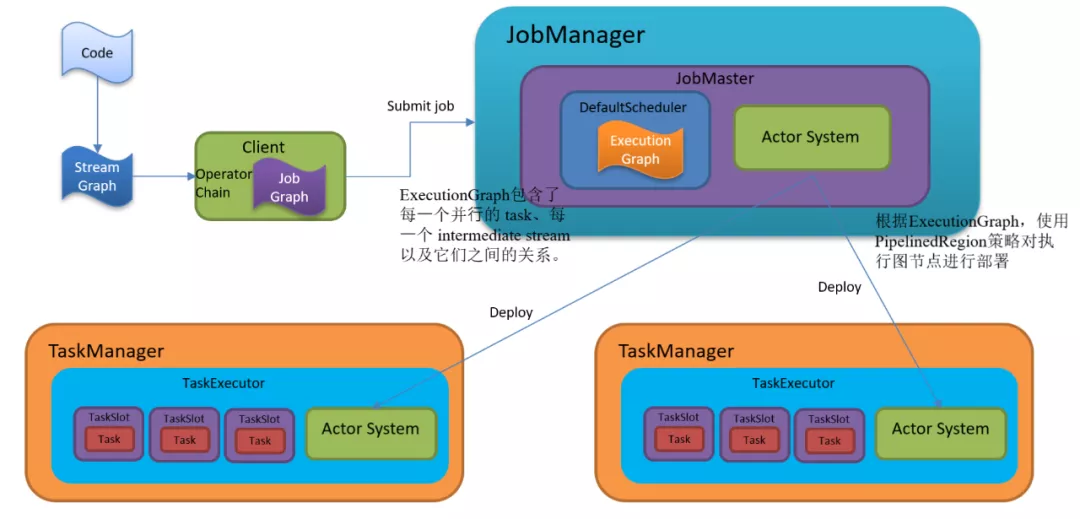
Flink 中的执行图可以分成四层:StreamGraph ->JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
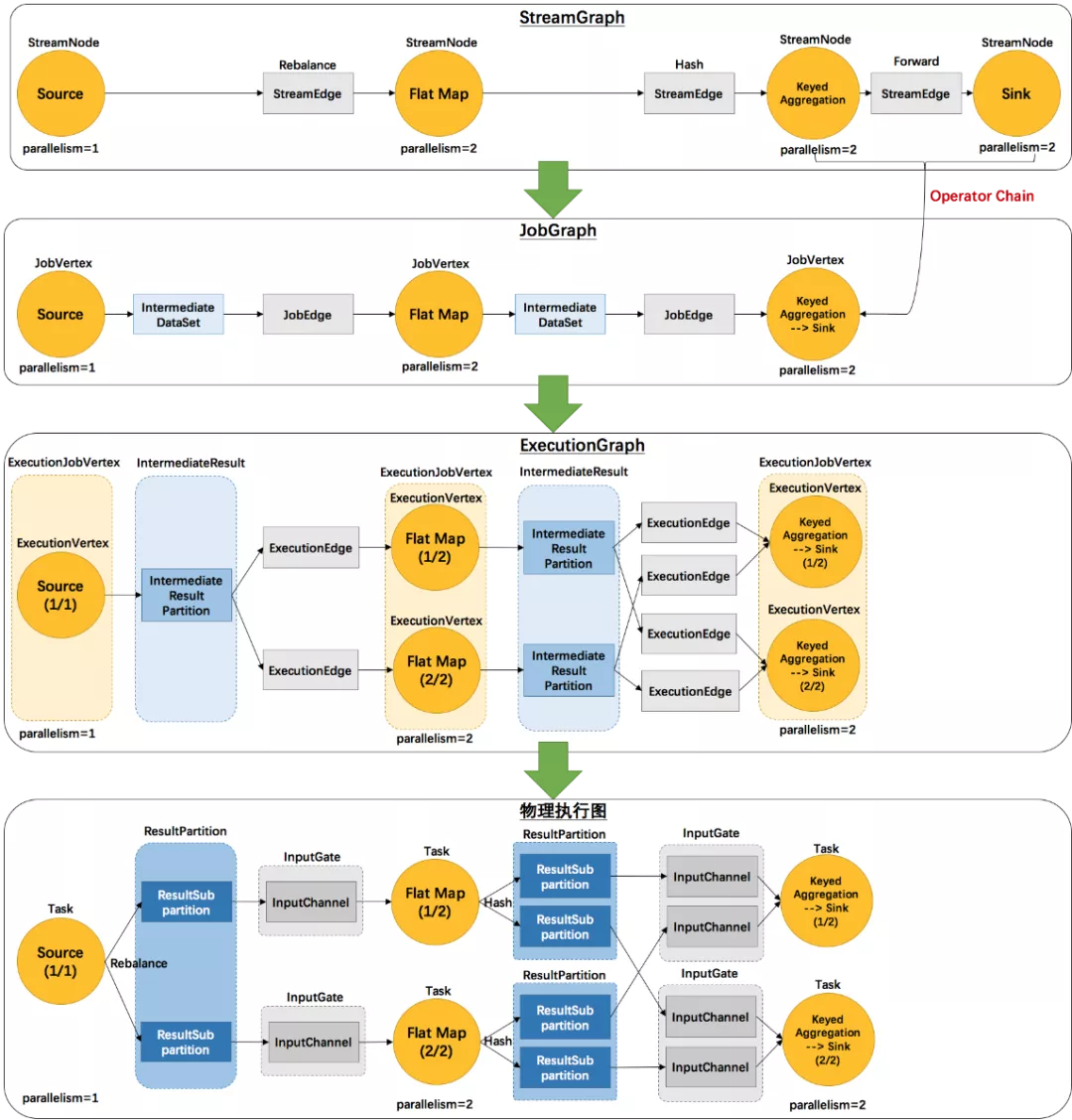
例如example里的SocketTextStreamWordCount并发度为2(Source为1个并发度)的四层执行图的演变过程如下图所示:
public static void main(String[] args) throws Exception {
// 检查输入
final ParameterTool params =ParameterTool.fromArgs(args);
...
// set up the execution environment
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
// get input data
DataStream<String> text =
env.socketTextStream(params.get("hostname"),params.getInt("port"), '\n', 0);
DataStream<Tuple2<String,Integer>> counts =
// split up the lines in pairs (2-tuples)containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field"0" and sum up tuple field "1"
.keyBy(0)
.sum(1);
counts.print();
// execute program
env.execute("WordCount fromSocketTextStream Example");
}
名词解释:
1)StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
(1)StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
(2)StreamEdge:表示连接两个StreamNode的边。
2)JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
(1)JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
(2)IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
(3)JobEdge:代表了job graph中的一条数据传输通道。source 是IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
3)ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
(1)ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
(2)ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是
IntermediateResultPartition。
(3)IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个
IntermediateResultPartition,其个数等于该operator的并发度。
(4)
IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
(5)ExecutionEdge:表示ExecutionVertex的输入,source是
IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
(6)Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过ExecutionAttemptID 来确定消息接受者。
从这些基本概念中,也可以看出以下⼏点:
- 由于每个 JobVertex 可能有多个IntermediateDataSet,所以每个ExecutionJobVertex可能有多个IntermediateResult,因此,每个ExecutionVertex也可能会包含多个IntermediateResultPartition;
- ExecutionEdge 这里主要的作⽤是把ExecutionVertex 和 IntermediateResultPartition 连接起来,表示它们之间的连接关系。
4)物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
(1)Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
(2)ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的
IntermediateResultPartition一一对应。
(3)ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和DistributionPattern 来决定。
(4)InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
(5)InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
2、StreamGraph在Client生成
调用用户代码中的
StreamExecutionEnvironment.execute()
-> execute(getJobName())
->execute(getStreamGraph(jobName))
->getStreamGraph(jobName, true)
StreamExecutionEnvironment.java
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
public StreamGraph generate() {
streamGraph = newStreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
shouldExecuteInBatchMode =shouldExecuteInBatchMode(runtimeExecutionMode);
configureStreamGraph(streamGraph);
alreadyTransformed = new HashMap<>();
for (Transformation<?>transformation: transformations) {
transform(transformation);
}
final StreamGraph builtStreamGraph =streamGraph;
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}
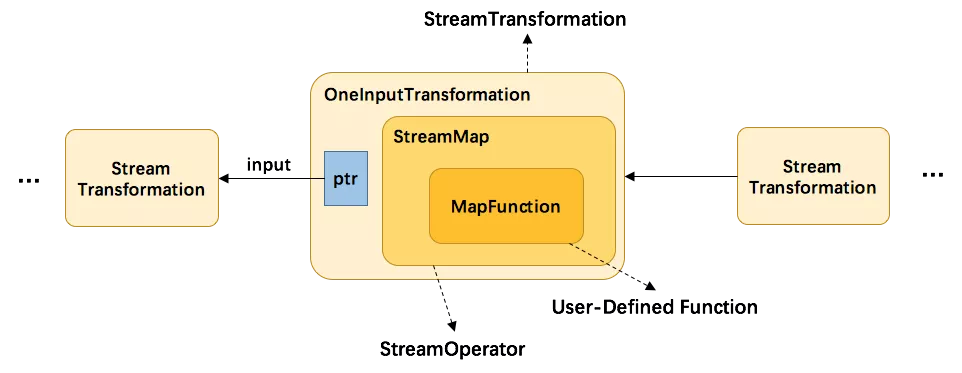
一个关键的参数是List<Transformation<?>> transformations。Transformation代表了从一个或多个DataStream生成新DataStream的操作。DataStream的底层其实就是一个 Transformation,描述了这个DataStream是怎么来的。
DataStream 上常见的 transformation 有 map、flatmap、filter等。这些transformation会构造出一棵StreamTransformation 树,通过这棵树转换成 StreamGraph。以map为例,分析List<Transformation<?>>transformations的数据:
DataStream.java
public <R>SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper) {
// 通过javareflection抽出mapper的返回值类型
TypeInformation<R> outType =TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(),true);
return map(mapper, outType);
}
public <R>SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper, TypeInformation<R> outputType) {
// 返回一个新的DataStream,SteramMap 为 StreamOperator 的实现类
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
public <R>SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R>outTypeInfo,
OneInputStreamOperator<T,R> operator) {
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R>outTypeInfo,
StreamOperatorFactory<R>operatorFactory) {
// read the output type of the inputTransform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// 新的transformation会连接上当前DataStream中的transformation,从而构建成一棵树
OneInputTransformation<T, R> resultTransform = newOneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked","rawtypes"})
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
// 所有的transformation都会存到 env 中,调用execute时遍历该list生成StreamGraph
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
从上方代码可以了解到,map转换将用户自定义的函数MapFunction包装到StreamMap这个Operator中,再将StreamMap包装到OneInputTransformation,最后该transformation存到env中,当调用env.execute时,遍历其中的transformation集合构造出StreamGraph。其分层实现如下图所示:
另外,并不是每一个 StreamTransformation 都会转换成 runtime 层中物理操作。有一些只是逻辑概念,比如 union、split/select、partition等。如下图所示的转换树,在运行时会优化成下方的操作图。
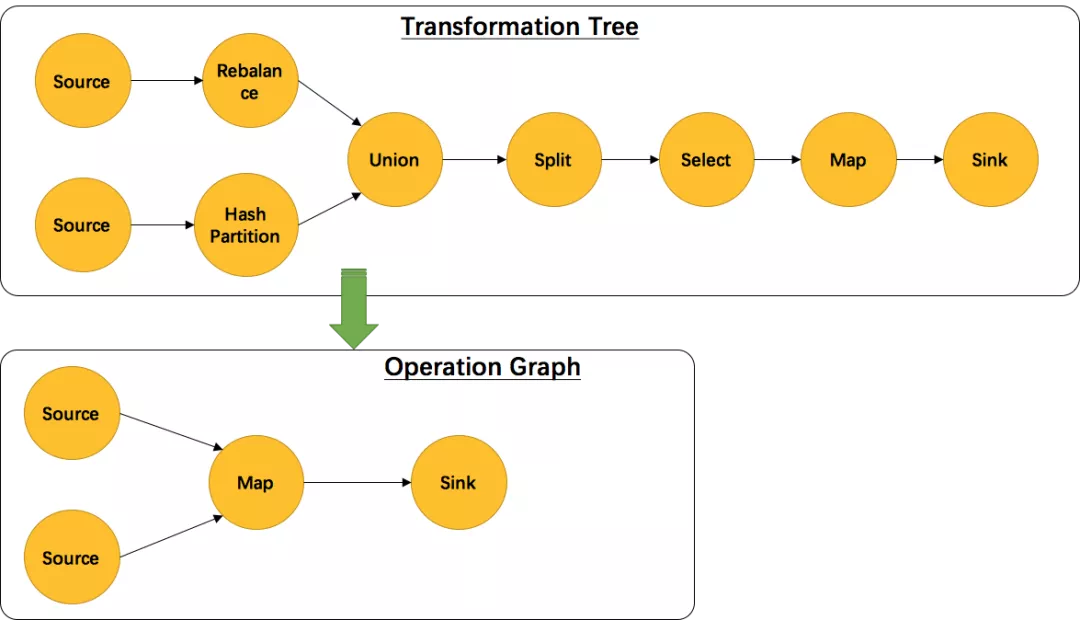
union、split/select(1.12已移除)、partition中的信息会被写入到 Source –> Map 的边中。通过源码也可以发现UnionTransformation,SplitTransformation(1.12移除),SelectTransformation(1.12移除),PartitionTransformation由于不包含具体的操作所以都没有StreamOperator成员变量,而其他StreamTransformation的子类基本上都有。
接着分析StreamGraph生成的源码:
StreamExecutionEnvironment.java-> generator() -> transform()
// 对每个transformation进行转换,转换成 StreamGraph 中的 StreamNode 和 StreamEdge
// 返回值为该transform的id集合,通常大小为1个(除FeedbackTransformation)
private Collection<Integer> transform(Transformation<?>transform) {
if(alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " +transform);
if (transform.getMaxParallelism() <=0) {
// if the max parallelismhasn't been set, then first use the job wide max parallelism
// from the ExecutionConfig.
int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
if (globalMaxParallelismFromConfig> 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to triggerexceptions about MissingTypeInfo
// 为了触发 MissingTypeInfo 的异常
transform.getOutputType();
@SuppressWarnings("unchecked")
final TransformationTranslator<?,Transformation<?>> translator =
(TransformationTranslator<?,Transformation<?>>) translatorMap.get(transform.getClass());
Collection<Integer>transformedIds;
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds =legacyTransform(transform);
}
// need this check because the iteratetransformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)){
alreadyTransformed.put(transform,transformedIds);
}
return transformedIds;
}
private Collection<Integer> translate(
finalTransformationTranslator<?, Transformation<?>> translator,
final Transformation<?>transform) {
checkNotNull(translator);
checkNotNull(transform);
final List<Collection<Integer>> allInputIds =getParentInputIds(transform.getInputs());
// the recursive call might havealready transformed this
if(alreadyTransformed.containsKey(transform)) {
returnalreadyTransformed.get(transform);
}
final String slotSharingGroup =determineSlotSharingGroup(
transform.getSlotSharingGroup(),
allInputIds.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()));
final TransformationTranslator.Contextcontext = new ContextImpl(
this, streamGraph,slotSharingGroup, configuration);
return shouldExecuteInBatchMode
?translator.translateForBatch(transform, context)
: translator.translateForStreaming(transform,context);
}
SimpleTransformationTranslator.java
public Collection<Integer> translateForStreaming(final Ttransformation, final Context context) {
checkNotNull(transformation);
checkNotNull(context);
final Collection<Integer>transformedIds =
translateForStreamingInternal(transformation,context);
configure(transformation, context);
return transformedIds;
}
Abstract OneInputTransformationTranslator.java
protected Collection<Integer> translateInternal(
final Transformation<OUT>transformation,
final StreamOperatorFactory<OUT> operatorFactory,
final TypeInformation<IN> inputType,
@Nullable final KeySelector<IN, ?> stateKeySelector,
@Nullable final TypeInformation<?> stateKeyType,
final Context context) {
checkNotNull(transformation);
checkNotNull(operatorFactory);
checkNotNull(inputType);
checkNotNull(context);
final StreamGraph streamGraph =context.getStreamGraph();
final String slotSharingGroup =context.getSlotSharingGroup();
final int transformationId =transformation.getId();
final ExecutionConfig executionConfig =streamGraph.getExecutionConfig();
// 添加StreamNode
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
operatorFactory,
inputType,
transformation.getOutputType(),
transformation.getName());
if (stateKeySelector != null) {
TypeSerializer<?>keySerializer = stateKeyType.createSerializer(executionConfig);
streamGraph.setOneInputStateKey(transformationId,stateKeySelector, keySerializer);
}
int parallelism =transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT
?transformation.getParallelism()
:executionConfig.getParallelism();
streamGraph.setParallelism(transformationId,parallelism);
streamGraph.setMaxParallelism(transformationId,transformation.getMaxParallelism());
final List<Transformation<?>> parentTransformations =transformation.getInputs();
checkState(
parentTransformations.size()== 1,
"Expected exactly oneinput transformation but found " + parentTransformations.size());
// 添加StreamEdge
for (Integer inputId: context.getStreamNodeIds(parentTransformations.get(0))){
streamGraph.addEdge(inputId, transformationId,0);
}
return Collections.singleton(transformationId);
}
该函数首先会对该transform的上游transform进行递归转换,确保上游的都已经完成了转化。然后通过transform构造出StreamNode,最后与上游的transform进行连接,构造出StreamNode。
最后再来看下对逻辑转换(partition、union等)的处理,如下是transformPartition函数的源码:
PartitionTransformationTranslator.java
protected Collection<Integer> translateForStreamingInternal(
final PartitionTransformation<OUT> transformation,
final Context context) {
return translateInternal(transformation, context);
}
private Collection<Integer> translateInternal(
final PartitionTransformation<OUT> transformation,
final Context context) {
checkNotNull(transformation);
checkNotNull(context);
final StreamGraph streamGraph =context.getStreamGraph();
final List<Transformation<?>> parentTransformations =transformation.getInputs();
checkState(
parentTransformations.size()== 1,
"Expected exactlyone input transformation but found " + parentTransformations.size());
final Transformation<?> input =parentTransformations.get(0);
List<Integer> resultIds = newArrayList<>();
for (Integer inputId:context.getStreamNodeIds(input)) {
// 生成一个新的虚拟id
final int virtualId = Transformation.getNewNodeId();
// 添加一个虚拟分区节点,不会生成 StreamNode
streamGraph.addVirtualPartitionNode(
inputId,
virtualId,
transformation.getPartitioner(),
transformation.getShuffleMode());
resultIds.add(virtualId);
}
return resultIds;
}
对partition的转换没有生成具体的StreamNode和StreamEdge,而是添加一个虚节点。当partition的下游transform(如map)添加edge时(调用StreamGraph.addEdge),会把partition信息写入到edge中。接前面map的流程:
AbstractOneInputTransformationTranslator.java-> translateInternal()
public void addEdge(Integer upStreamVertexID,Integer downStreamVertexID, int typeNumber) {
addEdgeInternal(upStreamVertexID,
downStreamVertexID,
typeNumber,
null,
newArrayList<String>(),
null,
null);
}
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?>partitioner,
List<String>outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
// 当上游是侧输出时,递归调用,并传入侧输出信息
if (virtualSideOutputNodes.containsKey(upStreamVertexID)){
int virtualId =upStreamVertexID;
upStreamVertexID =virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag =virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID,downStreamVertexID, typeNumber, partitioner, null, outputTag, shuffleMode);
//当上游是partition时,递归调用,并传入partitioner信息
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)){
int virtualId = upStreamVertexID;
upStreamVertexID =virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner =virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(upStreamVertexID,downStreamVertexID, typeNumber, partitioner, outputNames, outputTag,shuffleMode);
} else {
// 真正构建StreamEdge
StreamNode upstreamNode =getStreamNode(upStreamVertexID);
StreamNode downstreamNode =getStreamNode(downStreamVertexID);
// If no partitioner wasspecified and the parallelism of upstream and downstream
// operator matches useforward partitioning, use rebalance otherwise.
// 未指定partitioner的话,会为其选择 forward 或 rebalance 分区。
if (partitioner == null&& upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = newForwardPartitioner<Object>();
} else if (partitioner ==null) {
partitioner = newRebalancePartitioner<Object>();
}
// 健康检查,forward 分区必须要上下游的并发度一致
if (partitioner instanceofForwardPartitioner) {
if(upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow "+
"changeof parallelism. Upstream operation: " + upstreamNode + " parallelism:" + upstreamNode.getParallelism() +
",downstream operation: " + downstreamNode + " parallelism: " +downstreamNode.getParallelism() +
"You must use another partitioning strategy, such as broadcast, rebalance,shuffle or global.");
}
}
if (shuffleMode == null) {
shuffleMode =ShuffleMode.UNDEFINED;
}
// 创建StreamEdge
StreamEdge edge = newStreamEdge(upstreamNode, downstreamNode, typeNumber,
partitioner,outputTag, shuffleMode);
// 将该StreamEdge 添加到上游的输出,下游的输入
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
实例分析:
看一个实例:如下程序,是一个从 Source 中按行切分成单词并过滤输出的简单流程序,其中包含了逻辑转换:随机分区shuffle。分析该程序是如何生成StreamGraph的。
DataStream<String>text = env.socketTextStream(hostName, port); text.flatMap(newLineSplitter()).shuffle().filter(new HelloFilter()).print();
首先会在env中生成一棵transformation树,用List<Transformation<?>>保存。其结构图如下:

其中符号*为input指针,指向上游的transformation,从而形成了一棵transformation树。然后,通过调用
StreamGraphGenerator.generate(env,transformations)来生成StreamGraph。自底向上递归调用每一个transformation,也就是说处理顺序是Source->FlatMap->Shuffle->Filter->Sink。
如上图所示:
1)首先处理的Source,生成了Source的StreamNode。
2)然后处理的FlatMap,生成了FlatMap的StreamNode,并生成StreamEdge连接上游Source和FlatMap。由于上下游的并发度不一样(1:4),所以此处是Rebalance分区。
3)然后处理的Shuffle,由于是逻辑转换,并不会生成实际的节点。将partitioner信息暂存在virtuaPartitionNodes中。
4)在处理Filter时,生成了Filter的StreamNode。发现上游是shuffle,找到shuffle的上游FlatMap,创建StreamEdge与Filter相连。并把ShufflePartitioner的信息写到StreamEdge中。
5)最后处理Sink,创建Sink的StreamNode,并生成StreamEdge与上游Filter相连。由于上下游并发度一样(4:4),所以此处选择 Forward 分区。
最后可以通过 UI可视化来观察得到的 StreamGraph。
3、JobGraph在Client生成
StreamGraph 转变成 JobGraph 也是在Client完成,主要作了三件事:
- StreamNode 转成JobVertex。
- StreamEdge 转成JobEdge。
- JobEdge 和JobVertex 之间创建 IntermediateDataSet 来连接。
从创建完Yarn客户端应用程序后,看execute里的逻辑(yarn-per-job为例):
AbstractJobClusterExecutor.java
public CompletableFuture<JobClient> execute(@Nonnull finalPipeline pipeline, @Nonnull final Configuration configuration, @Nonnull finalClassLoader userCodeClassloader) throws Exception {
final JobGraph jobGraph =PipelineExecutorUtils.getJobGraph(pipeline,configuration);
… …
}
PipelineExecutorUtils.java
public static JobGraph getJobGraph(@Nonnull final Pipelinepipeline, @Nonnull final Configuration configuration) throws MalformedURLException {
checkNotNull(pipeline);
checkNotNull(configuration);
final ExecutionConfigAccessorexecutionConfigAccessor =ExecutionConfigAccessor.fromConfiguration(configuration);
final JobGraph jobGraph =FlinkPipelineTranslationUtil
.getJobGraph(pipeline, configuration,executionConfigAccessor.getParallelism());
… …
}
FlinkPipelineTranslationUtil.java
public static JobGraph getJobGraph(
Pipeline pipeline,
ConfigurationoptimizerConfiguration,
int defaultParallelism) {
FlinkPipelineTranslator pipelineTranslator = getPipelineTranslator(pipeline);
return pipelineTranslator.translateToJobGraph(pipeline,
optimizerConfiguration,
defaultParallelism);
}
StreamGraphTranslator.java
public JobGraph translateToJobGraph(
Pipeline pipeline,
ConfigurationoptimizerConfiguration,
int defaultParallelism) {
checkArgument(pipeline instanceofStreamGraph,
"Given pipelineis not a DataStream StreamGraph.");
StreamGraph streamGraph = (StreamGraph)pipeline;
return streamGraph.getJobGraph(null);
}
StreamGraph.java
public JobGraph getJobGraph(@Nullable JobID jobID) {
return StreamingJobGraphGenerator.createJobGraph(this, jobID);
}
StreamingJobGraphGenerator.java
public static JobGraph createJobGraph(StreamGraph streamGraph,@Nullable JobID jobID) {
return new StreamingJobGraphGenerator(streamGraph,jobID).createJobGraph();
}
看一下核心类
StreamingJobGraphGenerator的相关属性:
public class StreamingJobGraphGenerator {
… …
private StreamGraph streamGraph;
// id -> JobVertex
private Map<Integer, JobVertex>jobVertices;
private JobGraph jobGraph;
// 已经构建的JobVertex的id集合 private Collection<Integer>builtVertices;
// 物理边集合(排除了chain内部的边), 按创建顺序排序 private List<StreamEdge>physicalEdgesInOrder;
// 保存chain信息,部署时用来构建 OperatorChain,startNodeId -> (currentNodeId -> StreamConfig)
private Map<Integer, Map<Integer,StreamConfig>> chainedConfigs;
// 所有节点的配置信息,id -> StreamConfig
private Map<Integer, StreamConfig> vertexConfigs;
// 保存每个节点的名字,id -> chainedName
private Map<Integer, String> chainedNames;
private final Map<Integer, ResourceSpec> chainedMinResources;
private final Map<Integer, ResourceSpec> chainedPreferredResources;
private final Map<Integer,InputOutputFormatContainer> chainedInputOutputFormats;
private final StreamGraphHasher defaultStreamGraphHasher;
private final List<StreamGraphHasher> legacyStreamGraphHashers;
// 构造函数,入参只有 StreamGraph
public StreamingJobGraphGenerator(StreamGraphstreamGraph) {
this.streamGraph = streamGraph;
}
}
核心逻辑:根据 StreamGraph,生成 JobGraph:
private JobGraph createJobGraph() {
preValidate();
// make sure that all vertices startimmediately
// streaming 模式下,调度模式是所有节点(vertices)一起启动
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
jobGraph.enableApproximateLocalRecovery(streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes forthe nodes in order to identify them across
// submission iff they didn't change.
//广度优先遍历 StreamGraph 并且为每个SteamNode生成hash id,
// 保证如果提交的拓扑没有改变,则每次生成的hash都是一样的
Map<Integer, byte[]> hashes =defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes forbackwards compatibility
List<Map<Integer, byte[]>>legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher :legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
// 最重要的函数,生成JobVertex,JobEdge等,并尽可能地将多个节点chain在一起
setChaining(hashes, legacyHashes);
//将每个JobVertex的入边集合也序列化到该JobVertex的StreamConfig中
// (出边集合已经在setChaining的时候写入了)
setPhysicalEdges();
// 根据group name,为每个 JobVertex 指定所属的 SlotSharingGroup
//以及针对 Iteration的头尾设置 CoLocationGroup
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id ->streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id ->streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
// 配置checkpoint
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
JobGraphUtils.addUserArtifactEntries(streamGraph.getUserArtifacts(),jobGraph);
// set the ExecutionConfig last when ithas been finalized
try {
// 将StreamGraph 的 ExecutionConfig 序列化到 JobGraph 的配置中
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Couldnot serialize the ExecutionConfig." +
"Thisindicates that non-serializable types (like custom serializers) wereregistered");
}
return jobGraph;
}
StreamingJobGraphGenerator的成员变量都是为了辅助生成最终的JobGraph。
为所有节点生成一个唯一的hash id,如果节点在多次提交中没有改变(包括并发度、上下游等),那么这个id就不会改变,这主要用于故障恢复。
这里不能用 StreamNode.id来代替,因为这是一个从1开始的静态计数变量,同样的Job可能会得到不一样的id,如下代码示例的两个job是完全一样的,但是source的id却不一样了。
// 范例1:A.id=1 B.id=2 DataStream<String> A = ... DataStream<String> B = ... A.union(B).print(); // 范例2:A.id=2 B.id=1 DataStream<String> B = ... DataStream<String> A = ... A.union(B).print();
看一下最关键的chaining处理:
// 从source开始建立 node chains
private void setChaining(Map<Integer, byte[]>hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that runas inputs to another operator (chained inputs)
// from the sources that needs to runas the main (head) operator.
final Map<Integer,OperatorChainInfo> chainEntryPoints =buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
final Collection<OperatorChainInfo> initialEntryPoints = newArrayList<>(chainEntryPoints.values());
// iterate over a copy of the values,because this map gets concurrently modified
// 从source开始建⽴node chains
for (OperatorChainInfo info :initialEntryPoints) {
createChain(
info.getStartNodeId(),
1, // operators start at position 1 because 0 isfor chained source inputs
info,
chainEntryPoints);
}
}
// 构建node chains,返回当前节点的物理出边
// startNodeId != currentNodeId 时,说明currentNode是chain中的子节点
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfochainInfo,
final Map<Integer,OperatorChainInfo> chainEntryPoints) {
Integer startNodeId =chainInfo.getStartNodeId();
if(!builtVertices.contains(startNodeId)) {
// 过渡用的出边集合, 用来生成最终的 JobEdge, 注意不包括 chain 内部的边
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode =streamGraph.getStreamNode(currentNodeId);
// 将当前节点的出边分成 chainable 和 nonChainable 两类
for (StreamEdge outEdge : currentNode.getOutEdges()){
if(isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
for (StreamEdge chainable :chainableOutputs) {
transitiveOutEdges.addAll(
createChain(chainable.getTargetId(),chainIndex + 1, chainInfo, chainEntryPoints));
}
// 递归调用
for (StreamEdge nonChainable :nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1,// operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k)-> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
// 生成当前节点的显示名,如:"Keyed Aggregation -> Sink: Unnamed"
chainedNames.put(currentNodeId,createChainedName(currentNodeId, chainableOutputs,Optional.ofNullable(chainEntryPoints.get(currentNodeId))));
chainedMinResources.put(currentNodeId,createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId,createChainedPreferredResources(currentNodeId, chainableOutputs));
OperatorID currentOperatorId =chainInfo.addNodeToChain(currentNodeId, chainedNames.get(currentNodeId));
if(currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId,currentNode.getInputFormat());
}
if (currentNode.getOutputFormat()!= null) {
getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId,currentNode.getOutputFormat());
}
// 如果当前节点是起始节点, 则直接创建 JobVertex 并返回 StreamConfig, 否则先创建一个空的 StreamConfig
// createJobVertex 函数就是根据 StreamNode 创建对应的 JobVertex, 并返回了空的 StreamConfig
StreamConfig config =currentNodeId.equals(startNodeId)
?createJobVertex(startNodeId, chainInfo)
: newStreamConfig(new Configuration());
// 设置 JobVertex 的 StreamConfig, 基本上是序列化 StreamNode 中的配置到 StreamConfig 中.
// 其中包括序列化器, StreamOperator, Checkpoint 等相关配置
setVertexConfig(currentNodeId,config, chainableOutputs, nonChainableOutputs, chainInfo.getChainedSources());
if(currentNodeId.equals(startNodeId)) {
// 如果是chain的起始节点。(不是chain中的节点,也会被标记成 chain start)
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
// 将当前节点(headOfChain)与所有出边相连
for (StreamEdge edge :transitiveOutEdges) {
// 通过StreamEdge构建出JobEdge,创建IntermediateDataSet,
// 用来将JobVertex和JobEdge相连
connect(startNodeId,edge);
}
// 把物理出边写入配置, 部署时会用到
config.setOutEdgesInOrder(transitiveOutEdges);
// 将chain中所有子节点的StreamConfig
// 写入到 headOfChain 节点的 CHAINED_TASK_CONFIG 配置中
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
// 如果是 chain 中的子节点
chainedConfigs.computeIfAbsent(startNodeId,k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node =streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
// 将当前节点的StreamConfig添加到该chain的config集合中
chainedConfigs.get(startNodeId).put(currentNodeId,config);
}
config.setOperatorID(currentOperatorId);
if(chainableOutputs.isEmpty()) {
config.setChainEnd();
}
// 返回连往chain外部的出边集合
return transitiveOutEdges;
} else {
return newArrayList<>();
}
}
每个 JobVertex 都会对应一个可序列化的 StreamConfig, 用来发送给 JobManager 和 TaskManager。最后在 TaskManager 中起 Task 时,需要从这里面反序列化出所需要的配置信息, 其中就包括了含有用户代码的StreamOperator。
setChaining会对source调用createChain方法,该方法会递归调用下游节点,从而构建出node chains。createChain会分析当前节点的出边,根据Operator Chains中的chainable条件,将出边分成chainalbe和noChainable两类,并分别递归调用自身方法。之后会将StreamNode中的配置信息序列化到StreamConfig中。如果当前不是chain中的子节点,则会构建 JobVertex 和 JobEdge相连。如果是chain中的子节点,则会将StreamConfig添加到该chain的config集合中。一个node chains,除了 headOfChain node会生成对应的 JobVertex,其余的nodes都是以序列化的形式写入到StreamConfig中,并保存到headOfChain的 CHAINED_TASK_CONFIG 配置项中。直到部署时,才会取出并生成对应的ChainOperators。
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。


