Java中的集合(下)
### 11.3.3 List实现类的区别
#### 1、Vector和ArrayList的区别
核心类库中List接口有两个实现类:Vector和ArrayList。它们的底层物理结构都是数组,我们称为动态数组。
(1)ArrayList是新版的动态数组,线程不安全,效率高,Vector是旧版的动态数组,线程安全,效率低。
(2)动态数组的扩容机制不同,ArrayList扩容为原来的1.5倍,Vector扩容增加为原来的2倍。
(3)数组的初始化容量,如果在构建ArrayList与Vector的集合对象时,没有显式指定初始化容量,那么Vector的内部数组的初始容量默认为10,而ArrayList在JDK1.6及之前的版本也是10,JDK1.7之后的版本ArrayList初始化为长度为0的空数组,之后在添加第一个元素时,再创建长度为10的数组。
ArrayList在第1次添加时再创建数组是为了避免浪费。因为很多方法的返回值是ArrayList类型,需要返回一个ArrayList的对象,例如:后期从数据库查询对象的方法,返回值很多就是ArrayList。有可能你要查询的数据不存在,要么返回null,要么返回一个没有元素的ArrayList对象。
#### 2、ArrayList与LinkedList的区别
动态数组底层的物理结构是数组,因此根据索引访问的效率非常高。但是==非末尾==位置的插入和删除效率不高,因为涉及到移动元素。==末尾位置==的插入和删除不涉及移动元素。另外添加操作时涉及到扩容问题,就会增加时空消耗。
链表底层的物理结构是链表,因此根据索引访问的效率不高,但是插入和删除不需要移动元素,只需要修改前后元素的指向关系即可,而且链表的添加不会涉及到扩容问题。
## 11.4 栈和队列
### 11.4.1 栈
堆栈是一种先进后出(FILO:first in last out)或后进先出(LIFO:last in first out)的结构。
栈只是逻辑结构,其物理结构可以是数组,也可以是链表,即栈结构分为顺序栈和链式栈。
核心类库中的栈结构有Stack和LinkdeList。Stack就是顺序栈,它是Vector的子类。LinkedList是链式栈。
体现栈结构的操作方法:
* peek()方法:查看栈顶元素,不弹出
* pop()方法:弹出栈
* push(E e)方法:压入栈
```java
package com.atguigu.list;
import org.junit.Test;
import java.util.LinkedList;
import java.util.Stack;
public class TestStack {
@Test
public void test1(){
Stack<Integer> list = new Stack<>();
list.push(1);
list.push(2);
list.push(3);
System.out.println("list = " + list);
System.out.println("list.peek()=" + list.peek());
System.out.println("list.peek()=" + list.peek());
System.out.println("list.peek()=" + list.peek());
/*
System.out.println("list.pop() =" + list.pop());
System.out.println("list.pop() =" + list.pop());
System.out.println("list.pop() =" + list.pop());
System.out.println("list.pop() =" + list.pop());//java.util.NoSuchElementException
*/
while(!list.empty()){
System.out.println("list.pop() =" + list.pop());
}
}
@Test
public void test2(){
LinkedList<Integer> list = new LinkedList<>();
list.push(1);
list.push(2);
list.push(3);
System.out.println("list = " + list);
System.out.println("list.peek()=" + list.peek());
System.out.println("list.peek()=" + list.peek());
System.out.println("list.peek()=" + list.peek());
/*
System.out.println("list.pop() =" + list.pop());
System.out.println("list.pop() =" + list.pop());
System.out.println("list.pop() =" + list.pop());
System.out.println("list.pop() =" + list.pop());//java.util.NoSuchElementException
*/
while(!list.isEmpty()){
System.out.println("list.pop() =" + list.pop());
}
}
}
```### 11.4.2 队列
队列(Queue)是一种(但并非一定)先进先出(FIFO)的结构。
队列是逻辑结构,其物理结构可以是数组,也可以是链表。队列有普通队列、双端队列、并发队列等等,核心类库中的队列实现类有很多(后面会学到很多),LinkdeList是双端队列的实现类。
==Queue==除了基本的 `Collection`操作外,==队列==还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(`null` 或 `false`,具体取决于操作)。`Queue` 实现通常不允许插入 元素,尽管某些实现(如 )并不禁止插入 。即使在允许 null 的实现中,也不应该将 插入到 中,因为 也用作 方法的一个特殊返回值,表明队列不包含元素。
| | *抛出异常* | *返回特殊值* |
| ---- | ---------- | ------------ |
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 检查 | element() | peek() |
==Deque==,名称 *deque* 是“double ended queue==(双端队列)==”的缩写,通常读为“deck”。此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(`null` 或 `false`,具体取决于操作)。Deque接口的实现类有ArrayDeque和LinkedList,它们一个底层是使用数组实现,一个使用双向链表实现。
| | **第一个元素(头部)** | | **最后一个元素(尾部)** | |
| -------- | ---------------------- | ------------- | ------------------------ | ------------ |
| | *抛出异常* | *特殊值* | *抛出异常* | *特殊值* |
| **插入** | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| **移除** | removeFirst() | pollFirst() | removeLast() | pollLast() |
| **检查** | getFirst() | peekFirst() | getLast() | peekLast() |
此接口扩展了 `Queue`接口。在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 `Queue` 接口继承的方法完全等效于 `Deque` 方法,如下表所示:
| **`Queue` 方法** | **等效 `Deque` 方法** |
| ---------------- | --------------------- |
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
双端队列也可用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 `Stack` 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 `Deque` 方法,如下表所示:
| **堆栈方法** | **等效 `Deque` 方法** |
| ------------ | --------------------- |
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
结论:Deque接口的实现类既可以用作FILO堆栈使用,又可以用作FIFO队列使用。
```java
package com.atguigu.queue;
import java.util.LinkedList;
public class TestQueue {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.addLast("张三");
list.addLast("李四");
list.addLast("王五");
list.addLast("赵六");
while (!list.isEmpty()){
System.out.println("list.removeFirst()=" + list.removeFirst());
}
}
}
```
## 11.5 Map
### 11.5.1 概述
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即`java.util.Map<K,V>`接口。Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中HashMap是 Map 接口使用频率最高的实现类。
我们通过查看`Map`接口描述,发现`Map<K,V>`接口下的集合与`Collection<E>`接口下的集合,它们存储数据的形式不同。
* `Collection`中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
* `Map`中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
* `Collection`中的集合称为单列集合,`Map`中的集合称为双列集合。
* 需要注意的是,`Map`中的集合不能包含重复的键,值可以重复;每个键只能对应一个值(这个值可以是单个值,也可以是个数组或集合值)。
### 11.5.2 Map常用方法
1、添加操作
* V put(K key,V value):添加一对键值对
* void putAll(Map<? extends K,? extends V> m):添加一组键值对
2、删除
* void clear():清空map
* V remove(Object key):根据key删除一对键值对
* default boolean remove(Object key,Object value):删除匹配的(key,value)
3、修改value(JDK1.8新增)
- default V replace(K key, V value):找到目标key,替换value
- default boolean replace(K key,V oldValue,V newValue):找到目标(key,value),替换value
- default void replaceAll(BiFunction<? super K,? super V,? extends V> function):按照指定要求替换value
4、元素查询的操作
* V get(Object key):根据key返回value
* boolean containsKey(Object key):判断key是否存在
* boolean containsValue(Object value):判断value是否存在
* boolean isEmpty():判断map是否为空
* int size():获取键值对的数量
5、遍历
Map的遍历,不能支持foreach,因为Map接口没有继承java.lang.Iterable<T>接口。只能用如下方式遍历:
(1)分开遍历:
* 单独遍历所有key:Set<K> keySet()
* 单独遍历所有value:Collection<V> values()
(2)成对遍历:
* 遍历所有键值对:Set<Map.Entry<K,V>> entrySet()
* 遍历的是映射关系Map.Entry类型的对象,Map.Entry是Map接口的内部接口。每一种Map内部有自己的Map.Entry的实现类。在Map中存储数据,实际上是将Key---->value的数据存储在Map.Entry接口的实例中,再在Map集合中插入Map.Entry的实例化对象,如图示:
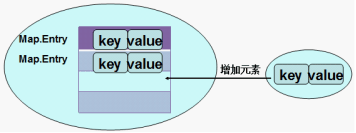
(3)调用forEach方法遍历
- default void forEach(BiConsumer<? super K,? super V> action)
```java
package com.atguigu.map;
import org.junit.Test;
import java.util.HashMap;
import java.util.function.BiFunction;
public class TestMapMethod {
@Test
public void test1(){
//创建 map对象
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("文章", "姚笛");
map.put("邓超", "孙俪");
System.out.println(map.size());
System.out.println(map);
}
@Test
public void test2(){
HashMap<String, String> map = new HashMap<String, String>();
//添加模范夫妻
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
System.out.println(map);
//删除键值对
map.remove("文章");
System.out.println(map);
map.remove("黄晓明","杨颖");
System.out.println(map);
}
@Test
public void test3(){
HashMap<String, String> map = new HashMap<String, String>();
//添加夫妻
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
map.put("张三", null);
System.out.println(map);
//修改value
map.replace("文章","姚笛");
System.out.println(map);
map.replace("黄晓明","杨颖", "angelababy");
System.out.println(map);
map.replaceAll(new BiFunction<String, String, String>() {
@Override
public String apply(String key, String value) {
return value == null ? "如花" : value;
}
});
System.out.println(map);
}
@Test
public void test4(){
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
// 想要查看 谁的媳妇 是谁
System.out.println(map.get("黄晓明"));
System.out.println(map.get("邓超"));
}
@Test
public void test4(){
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
//遍历所有key
System.out.println("所有key:");
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(key);
}
//遍历所有value
System.out.println("所有value:");
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
//遍历所有键值对
System.out.println("所有键值对:");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry);
}
//调用forEach方法遍历所有键值对
System.out.println("所有键值对:");
BiConsumer<String,String> c = new BiConsumer<>() {
@Override
public void accept(String key, String value) {
System.out.println(key+" vs "+value);
}
};
map.forEach(c);
}
}
```### 11.5.3 Map接口的实现类们
#### **1、HashMap和Hashtable**
HashMap和Hashtable都是哈希表。HashMap和Hashtable判断两个 key 相等的标准是:两个 key 的hashCode 值相等,并且 equals() 方法也返回 true。因此,为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
* Hashtable是线程安全的,任何非 null 对象都可以用作键或值。
* HashMap是线程不安全的,并允许使用 null 值和 null 键。
示例代码:添加员工姓名为key,薪资为value
```java
package com.atguigu.map;
import org.junit.Test;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
import java.util.Set;
public class TestHashMap {
@Test
public void test01(){
HashMap<String,Double> map = new HashMap<>();
map.put("张三", 10000.0);
//key相同,新的value会覆盖原来的value
//因为String重写了hashCode和equals方法
map.put("张三", 12000.0);
map.put("李四", 14000.0);
//HashMap支持key和value为null值
String name = null;
Double salary = null;
map.put(name, salary);
System.out.println(map);
}
@Test
public void test02(){
Hashtable<String,Double> map = new Hashtable<>();
map.put("张三", 10000.0);
//key相同,新的value会覆盖原来的value
//因为String重写了hashCode和equals方法
map.put("张三", 12000.0);
map.put("李四", 14000.0);
//Hashtable不支持key和value为null值
/*String name = null;
Double salary = null;
map.put(name, salary);*/
System.out.println(map);
}
}
```#### **2、LinkedHashMap**
LinkedHashMap 是 HashMap 的子类。此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
示例代码:添加员工姓名为key,薪资为value
```java
package com.atguigu.map;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class TestLinkedHashMap {
public static void main(String[] args) {
LinkedHashMap<String,Double> map = new LinkedHashMap<>();
map.put("张三", 10000.0);
//key相同,新的value会覆盖原来的value
//因为String重写了hashCode和equals方法
map.put("张三", 12000.0);
map.put("李四", 14000.0);
//HashMap支持key和value为null值
String name = null;
Double salary = null;
map.put(name, salary);
System.out.println(map);
}
}
```#### **3、TreeMap**
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
代码示例:添加员工姓名为key,薪资为value
```java
package com.atguigu.map;
import java.util.Comparator;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap;
import org.junit.Test;
public class TestTreeMap {
@Test
public void test1() {
TreeMap<String,Integer> map = new TreeMap<>();
map.put("Jack", 11000);
map.put("Alice", 12000);
map.put("zhangsan", 13000);
map.put("baitao", 14000);
map.put("Lucy", 15000);
//String实现了Comparable接口,默认按照Unicode编码值排序
System.out.println(map);
}
@Test
public void test2() {
//指定定制比较器Comparator,按照Unicode编码值排序,但是忽略大小写
TreeMap<String,Integer> map = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareToIgnoreCase(o2);
}
});
map.put("Jack", 11000);
map.put("Alice", 12000);
map.put("zhangsan", 13000);
map.put("baitao", 14000);
map.put("Lucy", 15000);
System.out.println(map);
}
}
```#### **4、Properties**
Properties 类是 Hashtable 的子类,Properties 可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
存取数据时,建议使用setProperty(String key,String value)方法和getProperty(String key)方法。
代码示例:
```java
package com.atguigu.map;
import org.junit.Test;
import java.util.Properties;
public class TestProperties {
@Test
public void test01() {
Properties properties = System.getProperties();
String fileEncoding = properties.getProperty("file.encoding");//当前源文件字符编码
System.out.println("fileEncoding = " + fileEncoding);
}
@Test
public void test02() {
Properties properties = new Properties();
properties.setProperty("user","chai");
properties.setProperty("password","123456");
System.out.println(properties);
}
}
```### 11.5.4 Set集合与Map集合的关系
Set的内部实现其实是一个Map。即HashSet的内部实现是一个HashMap,TreeSet的内部实现是一个TreeMap,LinkedHashSet的内部实现是一个LinkedHashMap。
部分源代码摘要:
HashSet源码:
```java
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//这个构造器是给子类LinkedHashSet调用的
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
```LinkedHashSet源码:
```java
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);//调用HashSet的某个构造器
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);//调用HashSet的某个构造器
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);//调用HashSet的某个构造器
addAll(c);
}
```TreeSet源码:
```java
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
```但是,咱们存到Set中只有一个元素,又是怎么变成(key,value)的呢?
以HashSet中的源码为例:
```java
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
```原来是,把添加到Set中的元素作为内部实现map的key,然后用一个常量对象PRESENT对象,作为value。
这是因为Set的元素不可重复和Map的key不可重复有相同特点。Map有一个方法keySet()可以返回所有key。
### 11.5.5 哈希表的原理分析
#### 1、二叉树了解
二叉树(Binary tree)是树形结构的一个重要类型。二叉树特点是每个结点最多只能有两棵子树,且有左右之分。许多实际问题抽象出来的数据结构往往是二叉树形式,二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。
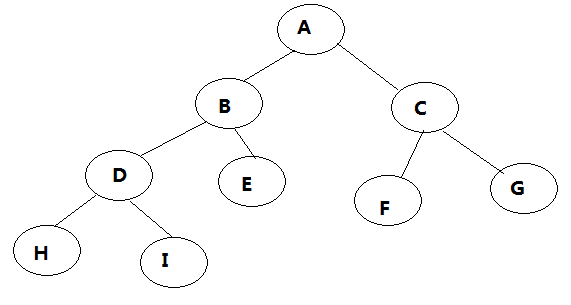
前序遍历:ABDHIECFG
中序遍历:HDIBEAFCG
后序遍历:HIDEBFGCA
以下是几种经典的二叉树:
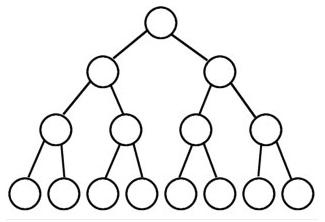
1、满二叉树: 除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。 第n层的结点数是2的n-1次方,总的结点个数是2的n次方-1
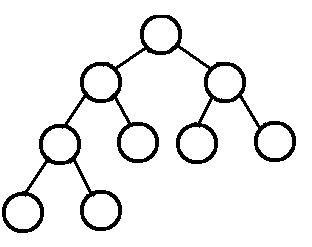
2、完全二叉树: 叶结点只能出现在最底层的两层,且最底层叶结点均处于次底层叶结点的左侧。
3、平衡二叉树:平衡二叉树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树, 但不要求非叶节点都有两个子结点 。平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。例如红黑树的要求:
- 节点是红色或者黑色
- 根节点是黑色
- 每个叶子的节点都是黑色的空节点(NULL)
- 每个红色节点的两个子节点都是黑色的。
- 从任意节点到其每个叶子的所有路径都包含相同的黑色节点数量。
当我们插入或删除节点时,可能会破坏已有的红黑树,使得它不满足以上5个要求,那么此时就需要进行处理:
1、recolor :将某个节点变红或变黑
2、rotation :将红黑树某些结点分支进行旋转(左旋或右旋)
使得它继续满足以上的5个要求。
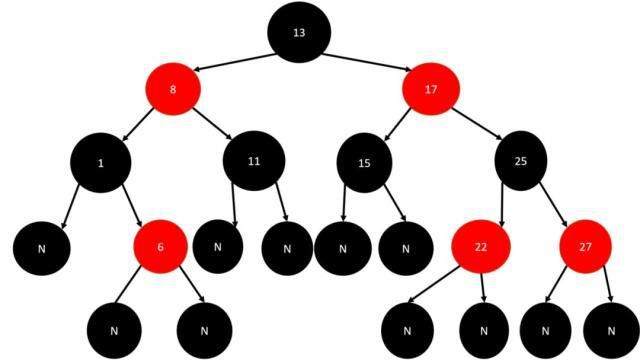
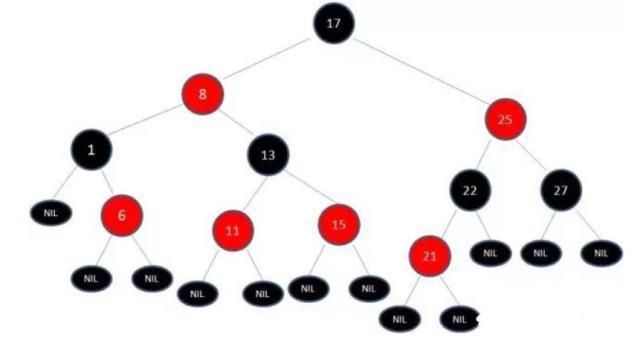
例如:插入了结点21之后,红黑树处理成:
#### 2、 哈希表的数据结构
请看PPT
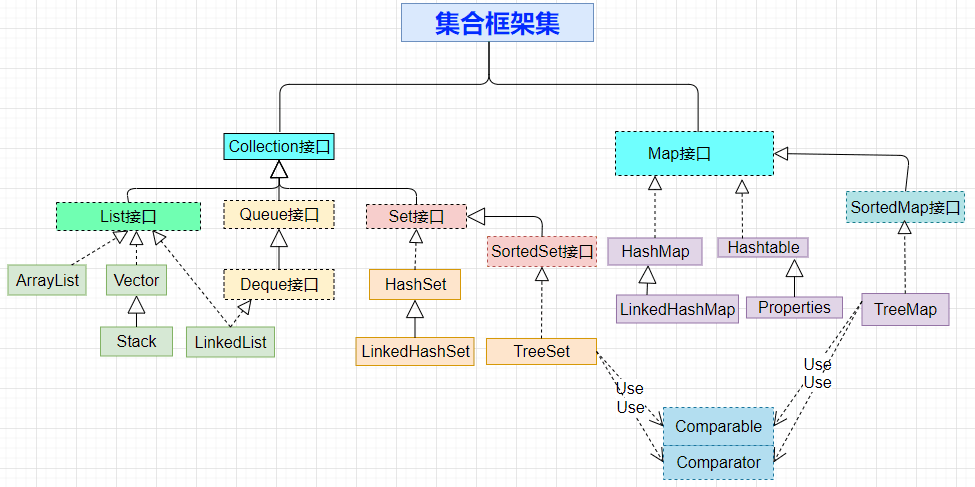
## 11.6 集合框架
## 11.7 Collections工具类
参考操作数组的工具类:Arrays。
Collections 是一个操作 Set、List 和 Map 等集合的工具类。Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法:
* public static <T> boolean addAll(Collection<? super T> c,T... elements)将所有指定元素添加到指定 collection 中。
* public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
* public static <T> int binarySearch(List<? extends T> list,T key,Comparator<? super T> c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。
* public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序
* public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者
* public static void reverse(List<?> list)反转指定列表List中元素的顺序。
* public static void shuffle(List<?> list) List 集合元素进行随机排序,类似洗牌
* public static <T extends Comparable<? super T>> void sort(List<T> list)根据元素的自然顺序对指定 List 集合元素按升序排序
* public static <T> void sort(List<T> list,Comparator<? super T> c)根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
* public static void swap(List<?> list,int i,int j)将指定 list 集合中的 i 处元素和 j 处元素进行交换
* public static int frequency(Collection<?> c,Object o)返回指定集合中指定元素的出现次数
* public static <T> void copy(List<? super T> dest,List<? extends T> src)将src中的内容复制到dest中
* public static <T> boolean replaceAll(List<T> list,T oldVal,T newVal):使用新值替换 List 对象的所有旧值
* Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
* Collections类中提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。
```java
package com.atguigu.collections;
import org.junit.Test;
import java.text.Collator;
import java.util.*;
public class TestCollections {
@Test
public void test11(){
/*
public static <T> boolean replaceAll(List<T> list,T oldVal,T newVal):使用新值替换 List 对象的所有旧值
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world","hello","hello");
Collections.replaceAll(list, "hello","chai");
System.out.println(list);
}
@Test
public void test10(){
List<Integer> list = new ArrayList<>();
for(int i=1; i<=5; i++){//1-5
list.add(i);
}
List<Integer> list2 = new ArrayList<>();
for(int i=11; i<=13; i++){//11-13
list2.add(i);
}
list.addAll(list2);
System.out.println(list);//[1, 2, 3, 4, 5, 11, 12, 13]
}
@Test
public void test09(){
/*
* public static <T> void copy(List<? super T> dest,List<? extends T> src)将src中的内容复制到dest中
*/
List<Integer> list = new ArrayList<>();
for(int i=1; i<=5; i++){//1-5
list.add(i);
}
List<Integer> list2 = new ArrayList<>();
for(int i=11; i<=13; i++){//11-13
list2.add(i);
}
Collections.copy(list, list2);
System.out.println(list);
List<Integer> list3 = new ArrayList<>();
for(int i=11; i<=20; i++){//11-20
list3.add(i);
}
Collections.copy(list, list3);//java.lang.IndexOutOfBoundsException: Source does not fit in dest
System.out.println(list);
}
@Test
public void test08(){
/*
public static int frequency(Collection<?> c,Object o)返回指定集合中指定元素的出现次数
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world","hello","hello");
int count = Collections.frequency(list, "hello");
System.out.println("count = " + count);
}
@Test
public void test07(){
/*
public static void swap(List<?> list,int i,int j)将指定 list 集合中的 i 处元素和 j 处元素进行交换
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
Collections.swap(list,0,2);
System.out.println(list);
}
@Test
public void test06() {
/*
* public static <T extends Comparable<? super T>> void sort(List<T> list)根据元素的自然顺序对指定 List 集合元素按升序排序
* public static <T> void sort(List<T> list,Comparator<? super T> c)根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
*/
List<Man> list = new ArrayList<>();
list.add(new Man("张三",23));
list.add(new Man("李四",24));
list.add(new Man("王五",25));
Collections.sort(list);
System.out.println(list);
Collections.sort(list, new Comparator<Man>() {
@Override
public int compare(Man o1, Man o2) {
return Collator.getInstance(Locale.CHINA).compare(o1.getName(),o2.getName());
}
});
System.out.println(list);
}
@Test
public void test05(){
/*
public static void shuffle(List<?> list) List 集合元素进行随机排序,类似洗牌,打乱顺序
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
Collections.shuffle(list);
System.out.println(list);
}
@Test
public void test04(){
/*
public static void reverse(List<?> list)反转指定列表List中元素的顺序。
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
System.out.println(list);
Collections.reverse(list);
System.out.println(list);
}
@Test
public void test03(){
/*
* public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
* <T extends Object & Comparable<? super T>>:要求T必须继承Object,又实现Comparable接口,或者T的父类实现Comparable接口
* 在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序
* public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp)
* 在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者
*
*/
List<Man> list = new ArrayList<>();
list.add(new Man("张三",23));
list.add(new Man("李四",24));
list.add(new Man("王五",25));
/*Man max = Collections.max(list);//要求Man实现Comparable接口,或者父类实现
System.out.println(max);*/
Man max = Collections.max(list, new Comparator<Man>() {
@Override
public int compare(Man o1, Man o2) {
return o2.getAge()-o2.getAge();
}
});
System.out.println(max);
}
@Test
public void test02(){
/*
* public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key)
* 要求List集合的元素类型 实现了 Comparable接口,这个实现可以是T类型本身也可以T的父类实现这个接口。
* 说明List中的元素支持自然排序功能。
* 在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
* public static <T> int binarySearch(List<? extends T> list,T key,Comparator<? super T> c)
* 说明List集合中元素的类型<=T,Comparator<? super T>说明要传入一个Comparator接口的实现类对象,实现类泛型的指定要求>=T
* 例如:List中存储的是Man(男)对象,T可以是Person类型,实现Comparator的时候可以是 Comparator<Person>
* 例如:List中存储的是Man(男)对象,T可以是Man类型,实现Comparator的时候可以是 Comparator<Person>
* 在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。
*
* 二分查找要求数组或List必须是“有大小顺序”。
* 二分查找的思路: 和[mid]元素比较,如果相同,就找到了,不相同要看大小关系,决定去左边还是右边继续查找。
*/
List<Man> list = new ArrayList<>();
list.add(new Man("张三",23));
list.add(new Man("李四",24));
list.add(new Man("王五",25));
// int index = Collections.binarySearch(list, new Man("王五", 25));//要求实现Comparable接口
// System.out.println(index);
int index = Collections.binarySearch(list, new Man("王五", 25), new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
});
System.out.println(index);
}
@Test
public void test01(){
/*
public static <T> boolean addAll(Collection<? super T> c,T... elements)将所有指定元素添加到指定 collection 中。
Collection的集合的元素类型必须>=T类型
*/
Collection<Object> coll = new ArrayList<>();
Collections.addAll(coll, "hello","java");
Collections.addAll(coll, 1,2,3,4);
Collection<String> coll2 = new ArrayList<>();
Collections.addAll(coll2, "hello","java");
// Collections.addAll(coll2, 1,2,3,4);//String和Integer之间没有父子类关系
}
}
```## 11.8 Arrays工具类
public static <T> List<T> asList(T... a):将指定元素添加到一个固定大小的列表中,并返回列表。
```java
@Test
public void test(){
List<String> list = Arrays.asList("hello", "java", "world");
System.out.println(list);
try {
list.add("chai");
} catch (Exception e) {
e.printStackTrace();
}
try {
list.remove("hello");
} catch (Exception e) {
e.printStackTrace();
}
}
```

