适学人群
-

小白人群
没有接触过互联网行业
渴望技术转型
转换行业的IT小白 -

高校毕业生
学习过一定的编程理论
希望提升经验
接触更广技术面 -

IT从业者
从事一定年限技术开发
目标突破自我
学习大数据技术
突破职业瓶颈 -

大数据从业者
从事大数据开发工作
希望了解更多
大数据开发技术
接触更多实时分析架构 -

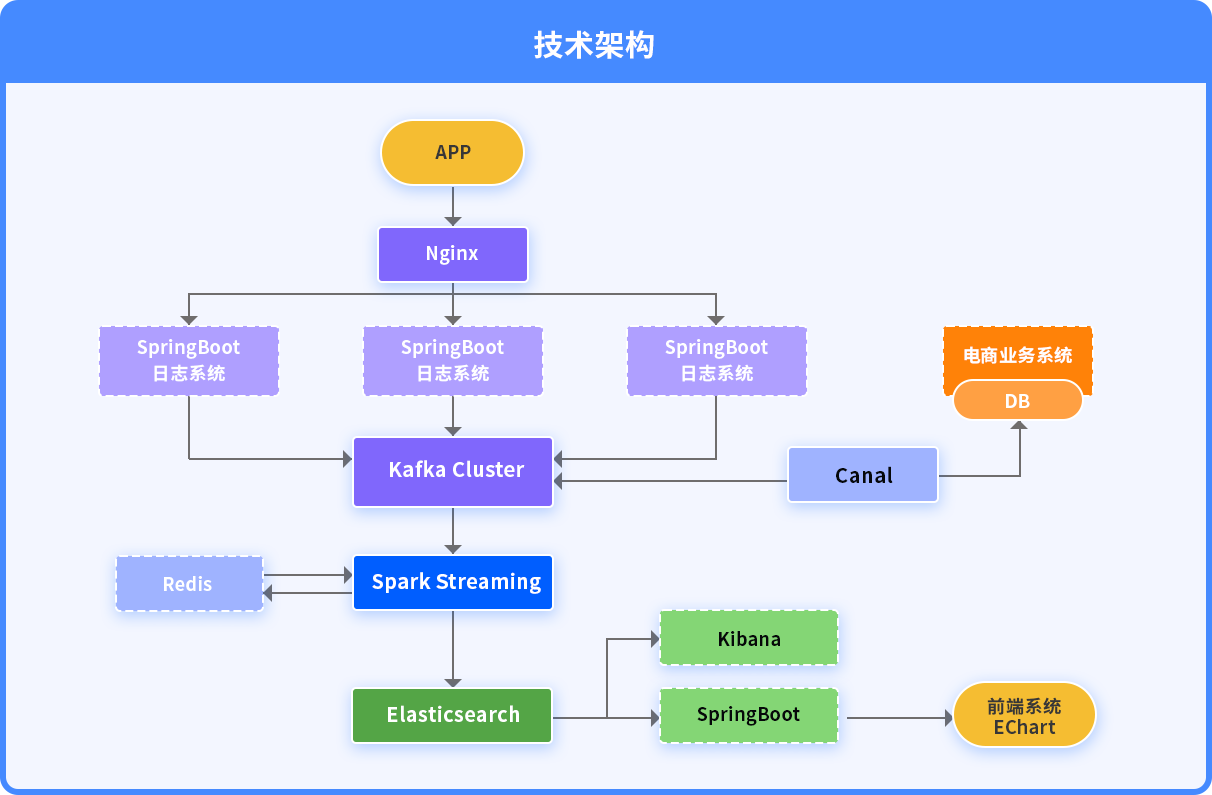
要求课程基础
Linux、Spark、Scala
ElasticSearch、Redis
Kafka等基础框架