适学人群
-

拥有多年从业经验的大数据从业者
渴望突破自我职业瓶颈,转型推荐系统工作 -

具有数学学习背景的高校毕业生
希望可以从实际项目中理解推荐系统
提升工作经验
拥有多年从业经验的大数据从业者
渴望突破自我职业瓶颈,转型推荐系统工作
具有数学学习背景的高校毕业生
希望可以从实际项目中理解推荐系统
提升工作经验
系统性梳理整合大数据技术知识与机器学习相关知识
深入了解推荐系统在电商企业中的实际应用
深入学习并掌握多种推荐算法
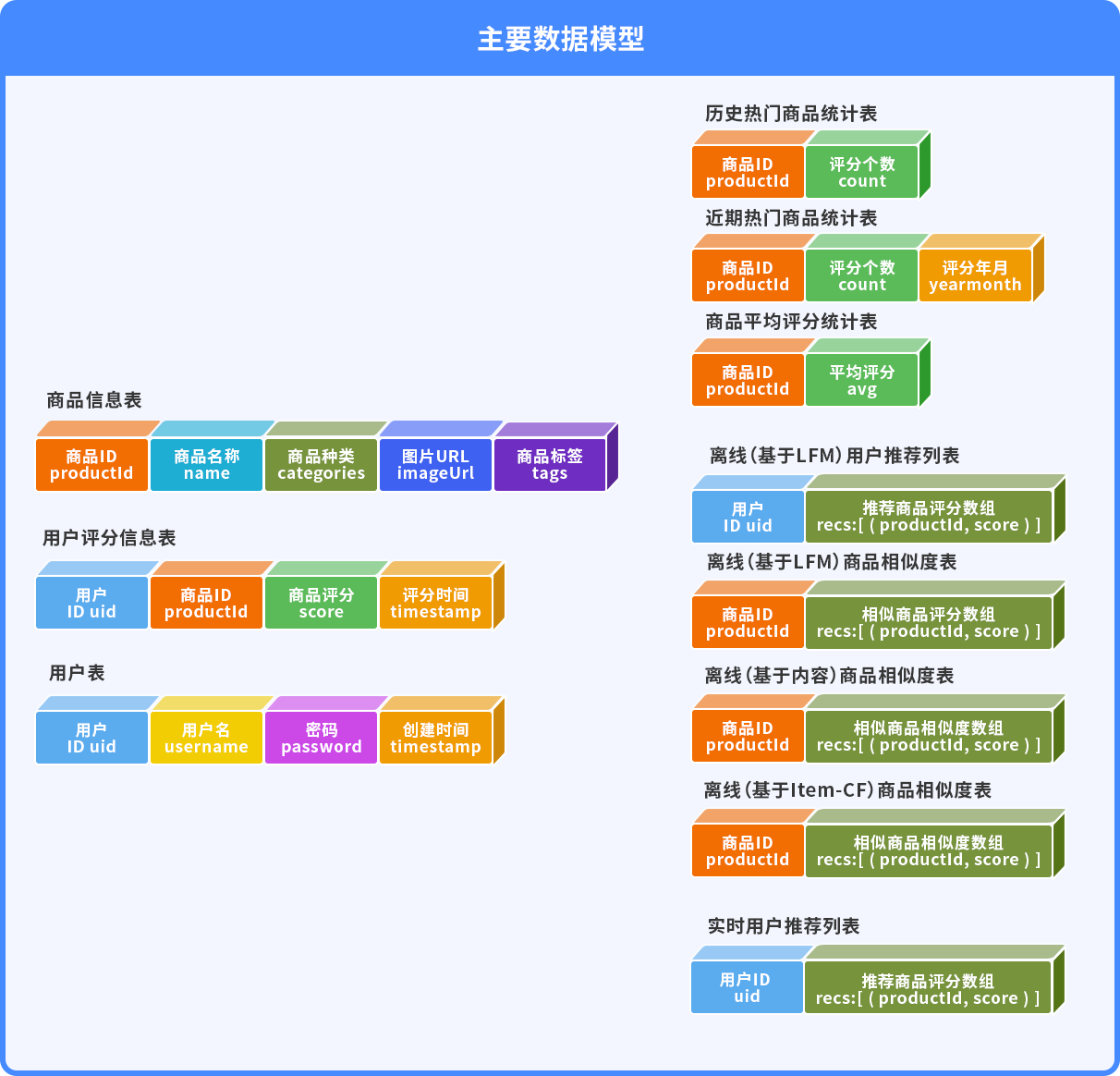
基于统计的离线推荐基于隐语义模型的离线推荐基于自定义模型的实时推荐基于Item-CF的离线相似推荐

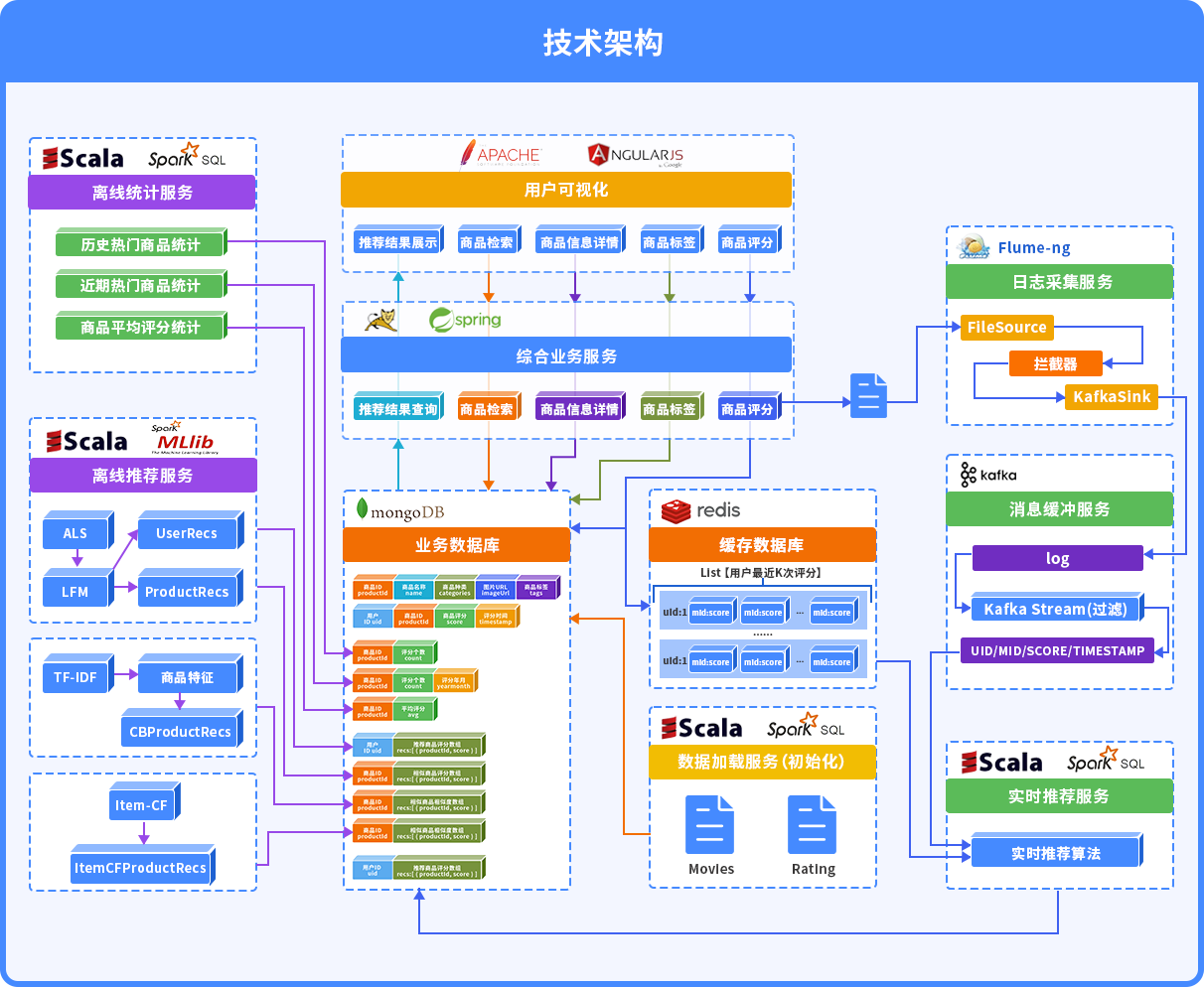
使用Flume、Kafka搭建实时数据采集系统,对多样化的用户行为数据和大体量的业务数据进行采集清洗和系统调优;

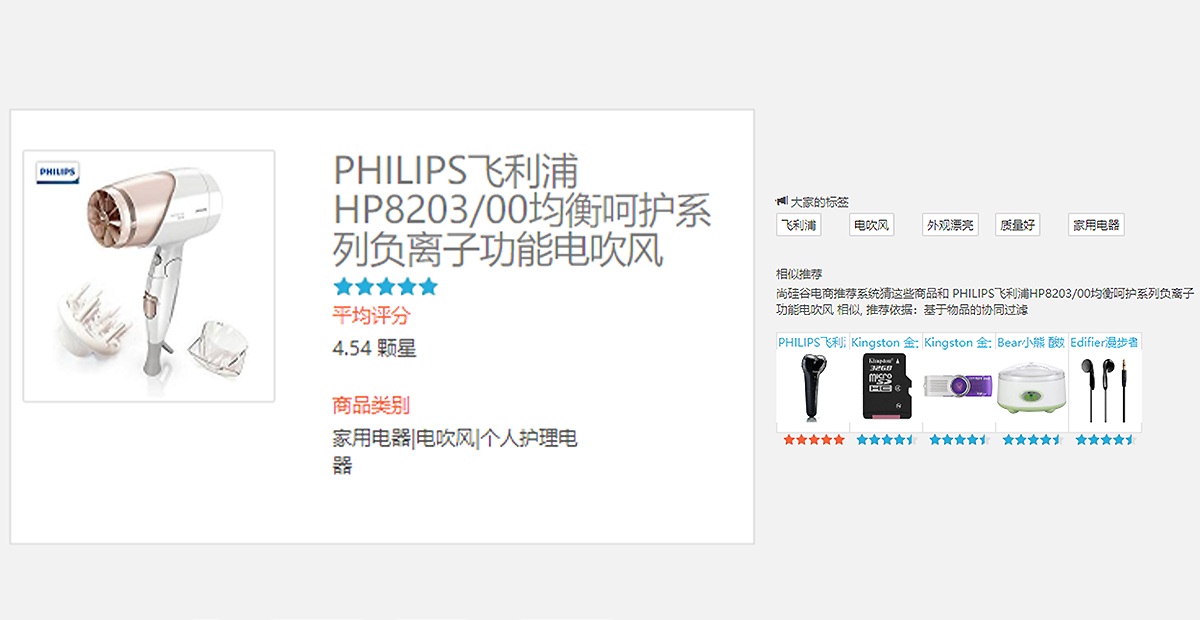
使用ALS算法对评分矩阵做矩阵分解,根据商品的隐语义特征计算商品之间的相似度,并将相似度做倒排索引,并将倒排数据持久化到MongoDB;

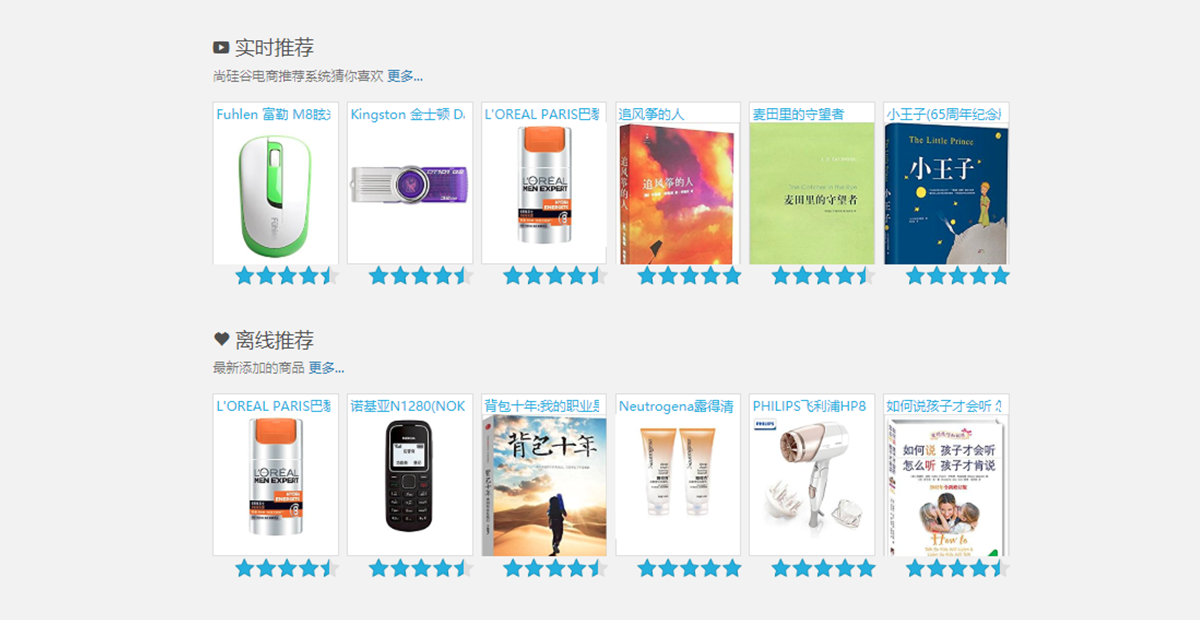
实时推荐:利用商品的相似度倒排,根据用户商品评分或者点击行为来做推荐,使用Spark Streaming来实时计算推荐优先级,然后存储到Redis中,提高用户的访问体验;

利用商品的标签数据,使用TF/IDF来计算商品之间的相似度,同样使用倒排的思路持久化道MongoDB;

使用Spark计算每个门类的平均评分商品来解决冷启动问题;

使用Spark将日志数据做分析和处理,然后持久化到MongoDB、ES等数据库中,实现data loader功能;

通过A/B测试来评估推荐结果;

优化Spark的计算效率,比如将一些数据进行.cache()操作缓存,对某些数据做broadcast广播到其他节点,加快运算;

使用Git进行版本管理,远程代码仓库使用自己搭建的gitlab;

将推荐系统引擎模块化:als矩阵分解的相似度计算、基于tfidf的相似度计算、实时推荐模块,每一个引擎都会产生一个推荐列表,对不同的引擎赋予不同的权重,然后合并列表,产生推荐数据。