尚硅谷大数据技术之Hadoop(MapReduce)(新)第3章 MapReduce框架原理
3.案例实操-方案一
1)增加一个WordcountCombiner类继承Reducer
package com.atguigu.mr.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1 汇总
int sum = 0;
for(IntWritable value :values){
sum += value.get();
}
v.set(sum);
// 2 写出
context.write(key, v);
}
}
2)在WordcountDriver驱动类中指定Combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);
4.案例实操-方案二
1)将WordcountReducer作为Combiner在WordcountDriver驱动类中指定
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑
job.setCombinerClass(WordcountReducer.class);
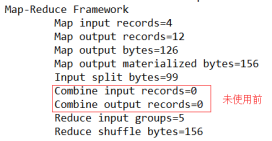
运行程序,如图4-16,4-17所示

3.3.9 GroupingComparator分组(辅助排序)
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 比较的业务逻辑
return result;
}
(3)创建一个构造将比较对象的类传给父类
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}


