还在为数据同步而苦恼吗?手把手教你实现canal数据同步(二)
Canal实战之Java客户端
入门代码
canal启动成功后,就可以通过java客户端读取binlog日志中的数据,并进行解析。
从头创建工程,过程略。。。。
- 添加依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
- ClientSample代码
package com.atguigu.canal.demo;
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
public class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接,connector也是canal数据操作客户端
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("172.16.116.100",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
// 链接对应的canal server
connector.connect();
// 客户端订阅,重复订阅时会更新对应的filter信息,这里订阅所有库的所有表
connector.subscribe(".*\\..*");
// 回滚到未进行 ack 的地方,下次fetch的时候,可以从最后一个没有 ack 的地方开始拿
connector.rollback();
int totalEmptyCount = 120;
// 循环遍历120次
while (emptyCount < totalEmptyCount) {
// 尝试拿batchSize条记录,有多少取多少,不会阻塞等待
Message message = connector.getWithoutAck(batchSize);
// 消息id
long batchId = message.getId();
// 实际获取记录数
int size = message.getEntries().size();
// 如果没有获取到消息
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
// 如果消息不为空,重置遍历。从0开始重新遍历
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
// 进行 batch id 的确认。
connector.ack(batchId); // 提交确认
// 回滚到未进行 ack 的地方,指定回滚具体的batchId;如果不指定batchId,回滚到未进行ack的地方
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
// 释放链接
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
// 如果是事务操作,直接忽略。EntryType常见取值:事务头BEGIN/事务尾END/数据ROWDATA
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChange = null;
try {
// 获取byte数据,并反序列化
rowChange = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChange.getEventType();
System.out.println("====================================begin========================================");
System.out.println(String.format("基本信息 binlog[%s:%s] , 表[%s.%s] , 操作: %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
// 如果是ddl或者是查询操作,直接打印sql
System.out.println(rowChange.getSql() + ";");
// 如果是删除、更新、新增操作解析出数据
for (RowData rowData : rowChange.getRowDatasList()) {
if (eventType == EventType.DELETE) {
// 删除操作,只有删除前的数据
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
// 新增数据,只有新增后的数据
printColumn(rowData.getAfterColumnsList());
} else {
// 更新数据:获取更新前后内容
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
System.out.println("------------------------------------end------------------------------------------");
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
- 运行Client
启动Canal Client后,可以从控制台从看到类似消息:
empty count : 1 empty count : 2 empty count : 3 empty count : 4
此时代表当前数据库无变更数据。
- 触发数据库变更
use test; CREATE TABLE `xdual` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `X` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`ID`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; insert into xdual(id,x) values(null,now());
可以从控制台看到:
empty count : 1 empty count : 2 empty count : 3 empty count : 4 ====================================begin======================================== 基本信息 binlog[mysql-bin.000001:15153] , 表[test.xdual] , 操作: CREATE CREATE TABLE `xdual` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `X` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`ID`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; ------------------------------------end------------------------------------------ ====================================begin======================================== 基本信息 binlog[mysql-bin.000001:15614] , 表[test.xdual] , 操作: INSERT ID : 1 update=true X : 2020-04-21 22:52:40 update=true ------------------------------------end------------------------------------------
模型设计
在了解具体API之前,需要提前了解下canal client的类设计,这样才可以正确的使用好canal。
- CanalConnector
javadoc查看:
http://alibaba.github.io/canal/apidocs/1.0.13/com/alibaba/otter/canal/client/CanalConnector.html
server/client交互协议:
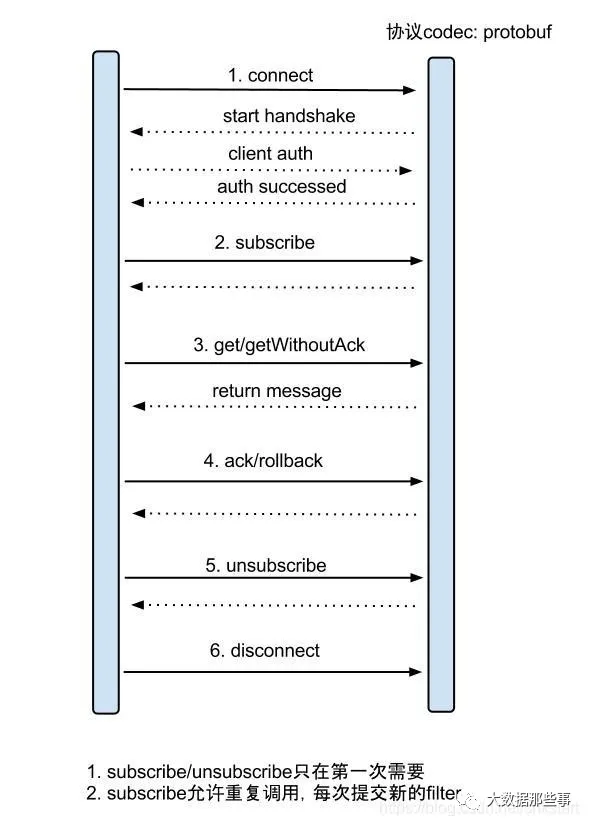
get/ack/rollback协议介绍:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识b. entries 具体的数据对象,可参见下面的数据介绍 - getWithoutAck(int batchSize, Long timeout, TimeUnit unit),相比于getWithoutAck(int batchSize),允许设定获取数据的timeout超时时间
a. 拿够batchSize条记录或者超过timeout时间b. timeout=0,阻塞等到足够的batchSize - void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
- void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
- 流式模型
流式api带来的异步响应模型:
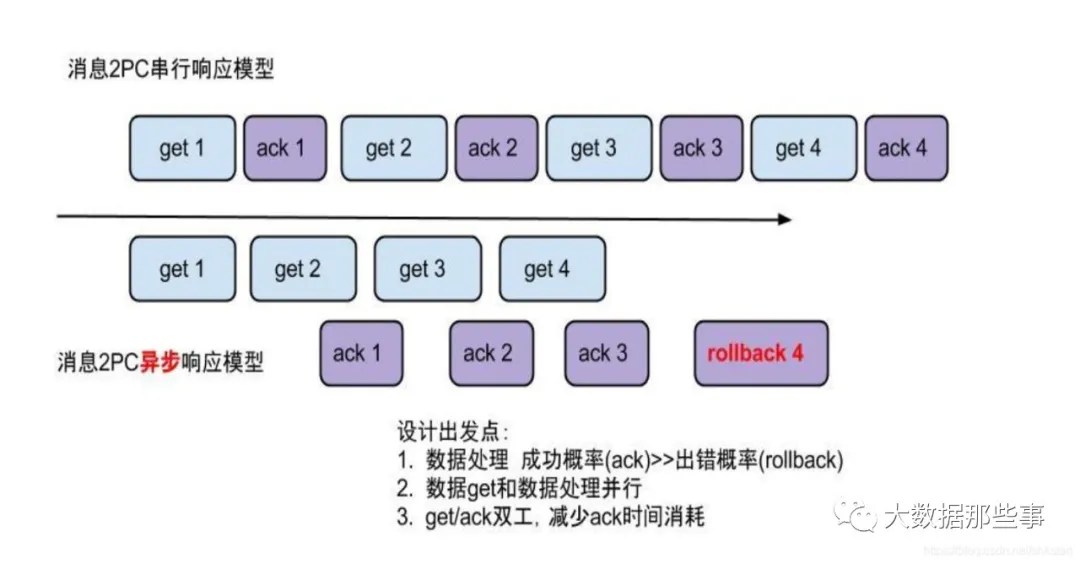
流式api设计:
- 每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
- 每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
- 进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cursor
- 一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
流式api设计的好处:
- get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
- get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)
- 数据对象Entry
数据对象格式简单介绍:
https://github.com/alibaba/canal/blob/master/protocol/src/main/java/com/alibaba/otter/canal/protocol/EntryProtocol.proto
Entry [每一条代表一条binlog数据]
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳,精确到秒]
schemaName
tableName
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组,变更前的数据字段]
afterColumns [Column类型的数组,变更后的数据字段]
Column
index
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为string文本]
说明:
- 可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全
- 可以提供ddl的变更语句
- insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
- 黑白名单配置
# table regex 设置白名单,如果在instance.properties配置文件中进行该项配置,则在代码中不应该再配置
# connector.subscribe(".*\\..*");,如果还在代码中配置,则配置文件将会失效!!!
canal.instance.filter.regex = .*\\..*
# table black regex 设置黑名单
canal.instance.filter.black.regex =
所以当你只关心部分库表更新时,设置了
canal.instance.filter.regex,一定不要在客户端调用CanalConnector.subscribe(".*\\..*"),不然等于没设置canal.instance.filter.regex。
如果一定要调用CanalConnector.subscribe(".*\\..*"),那么可以设置instance.properties的
canal.instance.filter.black.regex参数添加黑名单,过滤非关注库表。
========================================================
mysql 数据解析关注的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) 。
常见例子:
- 所有表:.* or .*\\..*
- canal schema下所有表:canal\\..*
- canal下的以canal打头的表:canal\\.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
以Redis为例数据同步
@SpringBootTest
class CanalDemoApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
private static final String KEY_PREFIX = "canal:test:";
@Test
void contextLoads() {
// 创建链接,connector也是canal数据操作客户端,默认端口号:11111
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("172.16.116.100",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
// 链接对应的canal server
connector.connect();
// 客户端订阅,重复订阅时会更新对应的filter信息,这里订阅所有库的所有表
connector.subscribe(".*\\..*");
// 回滚到未进行 ack 的地方,下次fetch的时候,可以从最后一个没有 ack 的地方开始拿
connector.rollback();
while (true) {
// 尝试拿batchSize条记录,有多少取多少,不会阻塞等待
Message message = connector.getWithoutAck(batchSize);
// 消息id
long batchId = message.getId();
// 实际获取记录数
int size = message.getEntries().size();
// 如果没有获取到消息
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
// 如果消息不为空,重置遍历。从0开始重新遍历
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
// 进行 batch id 的确认。
connector.ack(batchId); // 提交确认
// 回滚到未进行 ack 的地方,指定回滚具体的batchId;如果不指定batchId,回滚到未进行ack的地方
// connector.rollback(batchId); // 处理失败, 回滚数据
}
} finally {
// 释放链接
connector.disconnect();
}
}
private void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
// 如果是事务操作,直接忽略。EntryType常见取值:事务头BEGIN/事务尾END/数据ROWDATA
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
// 如果不是需要数据同步的表,直接忽略。
if (!StringUtils.equals(entry.getHeader().getSchemaName(), "test") || !StringUtils.equals(entry.getHeader().getTableName(), "user")){
continue;
}
CanalEntry.RowChange rowChange = null;
try {
// 获取byte数据,并反序列化
rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
CanalEntry.EventType eventType = rowChange.getEventType();
// 如果是删除、更新、新增操作解析出数据
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
// 操作前数据
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
// 操作后数据
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
if (eventType == CanalEntry.EventType.DELETE) {
// 删除操作,只有删除前的数据
if(beforeColumnsList.size() <= 0){
continue;
}
for (CanalEntry.Column column : beforeColumnsList) {
// 取主键作为key删除对应的缓存
if (column.getIsKey()){
this.redisTemplate.delete(KEY_PREFIX + column.getValue());
}
}
} else {
// 新增/更新数据,取操作后的数据。组装成json数据
if(afterColumnsList.size() <= 0){
continue;
}
JSONObject json=new JSONObject();
// 主键
String key = null;
for (CanalEntry.Column column : afterColumnsList) {
// 遍历字段放入json
json.put(underscoreToCamel(column.getName()), column.getValue());
// 如果是该字段是主键,取出该字段
if (column.getIsKey()){
key = column.getValue();
}
}
this.redisTemplate.opsForValue().set(KEY_PREFIX + key, json.toJSONString());
}
}
}
}
/**
* 下划线 转 驼峰
* @param param
* @return
*/
private String underscoreToCamel(String param){
if (param==null||"".equals(param.trim())){
return "";
}
int len=param.length();
StringBuilder sb=new StringBuilder(len);
for (int i = 0; i < len; i++) {
char c = Character.toLowerCase(param.charAt(i));
if (c == '_'){
if (++i<len){
sb.append(Character.toUpperCase(param.charAt(i)));
}
}else{
sb.append(c);
}
}
return sb.toString();
}
}
想要了解跟多关于
课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。


