Hadoop运维工具箱之HDFS异构存储
异构存储主要解决,不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
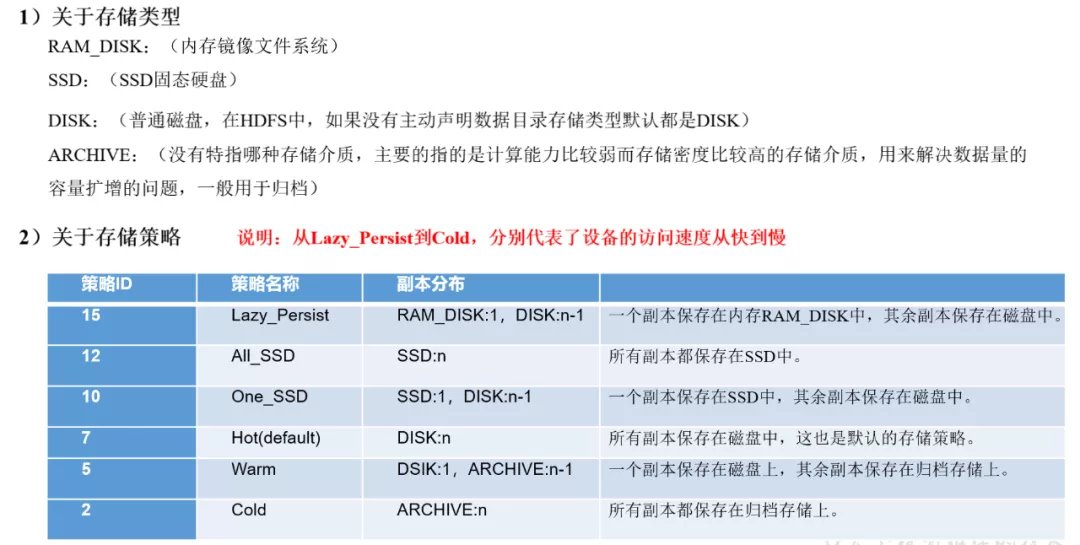
Hadoop的存储类型和存储策略有;
一、异构存储shell操作
1、查看当前有哪些存储策略可以用
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies-listPolicies
2、为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -pathxxx -policy xxx
3、获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx
4、取消存储策略;执行该命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOT
hdfs storagepolicies -unsetStoragePolicy-path xxx
5、查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations
6、查看集群节点
hadoop dfsadmin -report
二、测试环境准备
1、测试环境描述
服务器规模:5台
集群配置:副本数为2,创建好带有存储类型的目录(提前创建)
集群规划:
|
节点 |
存储类型分配 |
|
hadoop102 |
RAM_DISK,SSD |
|
hadoop103 |
SSD,DISK |
|
hadoop104 |
DISK,RAM_DISK |
|
hadoop105 |
ARCHIVE |
|
hadoop106 |
ARCHIVE |
2、配置文件信息
(1)为hadoop102节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk</value>
</property>
(2)为hadoop103节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
(3)为hadoop104节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[RAM_DISK]file:///opt/module/hdfsdata/ram_disk,[DISK]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
(4)为hadoop105节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value>
</property>
(5)为hadoop106节点的hdfs-site.xml添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value>
</property>
3、数据准备
(1)启动集群
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format [atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
(2)并在HDFS上创建文件目录
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /hdfsdata
(3)并将文件资料上传
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/NOTICE.txt /hdfsdata
三、Hot存储策略案例
1、最开始我们未设置存储策略的情况下,我们获取该目录的存储策略
[atguigu@hadoop102 hadoop-3.1.3]$hdfs storagepolicies -getStoragePolicy -path /hdfsdata
2、我们查看上传的文件块分布
[atguigu@hadoop102 hadoop-3.1.3]$hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
未设置存储策略,所有文件块都存储在DISK下。所以,默认存储策略为HOT。
四、Warm存储策略案例
1、接下来我们为数据降温
[atguigu@hadoop102 hadoop-3.1.3]$hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy WARM
2、再次查看文件块分布,我们可以看到文件块依然放在原处。
[atguigu@hadoop102 hadoop-3.1.3]$hdfs fsck /hdfsdata -files -blocks -locations
3、我们需要让他HDFS按照存储策略自行移动文件块
[atguigu@hadoop102 hadoop-3.1.3]$hdfs mover /hdfsdata
4、再次查看文件块分布,
[atguigu@hadoop102 hadoop-3.1.3]$hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
文件块一半在DISK,一半在ARCHIVE,符合我们设置的WARM策略
五、Cold策略测试
1、我们继续将数据降温为cold
[atguigu@hadoop102 hadoop-3.1.3]$hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy COLD
注意:当我们将目录设置为COLD并且我们未配置ARCHIVE存储目录的情况下,不可以向该目录直接上传文件,会报出异常。
2、手动转移
[atguigu@hadoop102 hadoop-3.1.3]$hdfs mover /hdfsdata
3、检查文件块的分布
[atguigu@hadoop102 hadoop-3.1.3]$bin/hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.106:9866,DS-827b3f8b-84d7-47c6-8a14-0166096f919d,ARCHIVE]]
所有文件块都在ARCHIVE,符合COLD存储策略。
六、One_SSD策略测试
1、接下来我们将存储策略从默认的HOT更改为One_SSD
[atguigu@hadoop102 hadoop-3.1.3]$hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy One_SSD
2、手动转移文件块
[atguigu@hadoop102 hadoop-3.1.3]$hdfs mover /hdfsdata
3、转移完成后,我们查看文件块分布,
[atguigu@hadoop102 hadoop-3.1.3]$bin/hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]
文件块分布为一半在SSD,一半在DISK,符合One_SSD存储策略。
七、All_SSD策略测试
1、接下来,我们再将存储策略更改为All_SSD
[atguigu@hadoop102 hadoop-3.1.3]$hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy All_SSD
2、手动转移文件块
[atguigu@hadoop102 hadoop-3.1.3]$hdfs mover /hdfsdata
3、查看文件块分布,我们可以看到,
[atguigu@hadoop102 hadoop-3.1.3]$bin/hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.102:9866,DS-c997cfb4-16dc-4e69-a0c4-9411a1b0c1eb,SSD], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]
所有的文件块都存储在SSD,符合All_SSD存储策略。
八、Lazy_Persist策略测试
1、继续改变策略,将存储策略改为lazy_persist
[atguigu@hadoop102 hadoop-3.1.3]$hdfs storagepolicies -setStoragePolicy -path /hdfsdata -policy lazy_persist
2、手动转移文件块
[atguigu@hadoop102 hadoop-3.1.3]$ hdfsmover /hdfsdata
3、查看文件块分布
[atguigu@hadoop102 hadoop-3.1.3]$hdfs fsck /hdfsdata -files -blocks -locations [DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
这里我们发现所有的文件块都是存储在DISK,按照理论一个副本存储在RAM_DISK,其他副本存储在DISK中,这是因为,我们还需要配置“
dfs.datanode.max.locked.memory”,“dfs.block.size”参数。
那么出现存储策略为LAZY_PERSIST时,文件块副本都存储在DISK上的原因有如下两点:
1、当客户端所在的DataNode节点没有RAM_DISK时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
2、当客户端所在的DataNode有RAM_DISK,但“
dfs.datanode.max.locked.memory”参数值未设置或者设置过小(小于“dfs.block.size”参数值)时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
但是由于虚拟机的“maxlocked memory”为64KB,所以,如果参数配置过大,还会报出错误:
ERRORorg.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.lang.RuntimeException: Cannotstart datanode because the configured max locked memory size(dfs.datanode.max.locked.memory) of 209715200 bytes is more than the datanode'savailable RLIMIT_MEMLOCK ulimit of 65536 bytes.
我们可以通过该命令查询此参数的内存
[atguigu@hadoop102 hadoop-3.1.3]$ulimit -a max locked memory (kbytes,-l) 64 想要了解跟多关于
课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。


