大数据项目之电影推荐系统Azkaban环境配置
Azkaban(单节点)环境配置
1 安装Git
|
// 安装GIT [bigdata@linux ~]$ sudo yum install git // 通过git下载Azkaban源代码 [bigdata@linux ~]$ git clone https://github.com/azkaban/azkaban.git // 进入azkaban目录 [bigdata@linux ~]$ cd azkaban/ // 切换到3.36.0版本 [bigdata@linux azkaban]$ git checkout -b 3.36.0
|
2 编译Azkaban
详细请参照:https://github.com/azkaban/azkaban
|
// 安装编译环境 [bigdata@linux azkaban]$sudo yum install gcc [bigdata@linux azkaban]$sudo yum install -y gcc-c++* // 执行编译命令 [bigdata@linux azkaban]$ ./gradlew clean build |
3 部署Azkaban Solo
|
// 将编译好的azkaban中的azkaban-solo-server-3.36.0.tar.gz拷贝到根目录 [bigdata@linux azkaban]$ cp ./azkaban-solo-server/build/distributions/azkaban-solo-server-3.36.0.tar.gz ~/ // 解压azkaban-solo-server-3.36.0.tar.gz到安装目录 [bigdata@linux ~]$ tar -xf azkaban-solo-server-3.36.0.tar.gz -C ./cluster // 启动Azkaban Solo单节点服务 [bigdata@linux azkaban-solo-server-3.36.0]$ bin/azkaban-solo-start.sh // 访问azkaban服务,通过浏览器代开http://ip:8081,通过用户名:azkaban,密码azkaban登录。
// 关闭Azkaban服务 [bigdata@linux azkaban-solo-server-3.36.0]$ bin/azkaban-solo-shutdown.sh |
Spark(单节点)环境配置
|
// 通过wget下载zookeeper安装包 [bigdata@linux ~]$ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.1.1-bin-hadoop2.7.tgz // 将spark解压到安装目录 [bigdata@linux ~]$ tar –xf spark-2.1.1-bin-hadoop2.7.tgz –C ./cluster // 进入spark安装目录 [bigdata@linux cluster]$ cd spark-2.1.1-bin-hadoop2.7/ // 复制slave配置文件 [bigdata@linux spark-2.1.1-bin-hadoop2.7]$ cp ./conf/slaves.template ./conf/slaves // 修改slave配置文件 [bigdata@linux spark-2.1.1-bin-hadoop2.7]$ vim ./conf/slaves linux #在文件最后将本机主机名进行添加 // 复制Spark-Env配置文件 [bigdata@linux spark-2.1.1-bin-hadoop2.7]$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh SPARK_MASTER_HOST=linux #添加spark master的主机名 SPARK_MASTER_PORT=7077 #添加spark master的端口号
|
安装完成之后,启动Spark
|
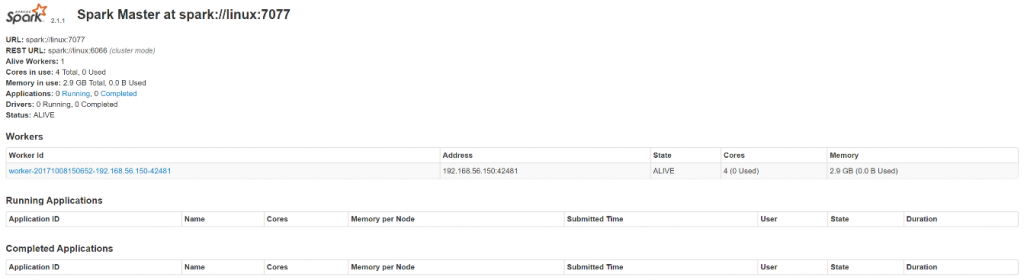
// 启动Spark集群 [bigdata@linux spark-2.1.1-bin-hadoop2.7]$ sbin/start-all.sh // 访问Spark集群,浏览器访问http://linux:8080
// 关闭Spark集群 [bigdata@linux spark-2.1.1-bin-hadoop2.7]$ sbin/stop-all.sh |
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。


