大数据培训技术ClickHouse表引擎Distributed
Distributed
分布式引擎,本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
Distributed(cluster_name, database, table [, sharding_key])
参数解析:
cluster_name - 服务器配置文件中的集群名,在/etc/metrika.xml中配置的
database – 数据库名
table – 表名
sharding_key – 数据分片键
案例演示:
1)在hadoop102,hadoop103,hadoop104上分别创建一个表t
:)create table t(id UInt16, name String) ENGINE=TinyLog;
2)在三台机器的t表中插入一些数据
:)insert into t(id, name) values (1, 'zhangsan');
:)insert into t(id, name) values (2, 'lisi');
3)在hadoop102上创建分布式表
:)create table dis_table(id UInt16, name String) ENGINE=Distributed(perftest_3shards_1replicas, default, t, id);
4)往dis_table中插入数据
:) insert into dis_table select * from t
5)查看数据量
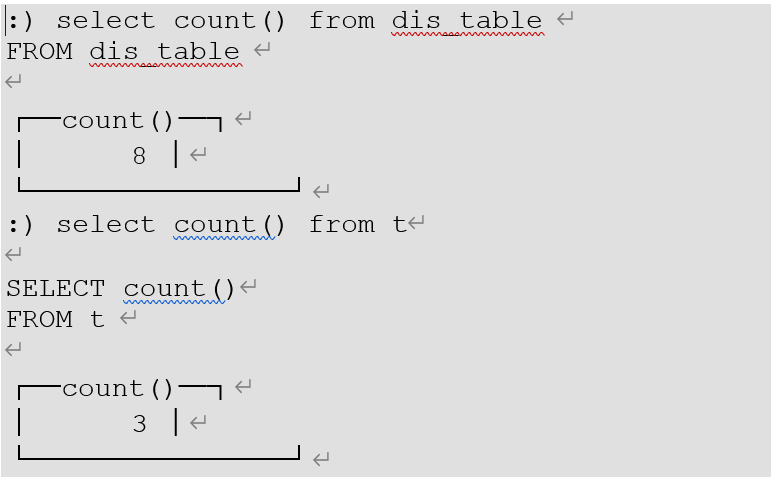
可以看到每个节点大约有1/3的数据
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。


