尚硅谷大数据技术之Hadoop(MapReduce)(新)第3章 MapReduce框架原理
2.需求分析
通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联,如图4-20所示。
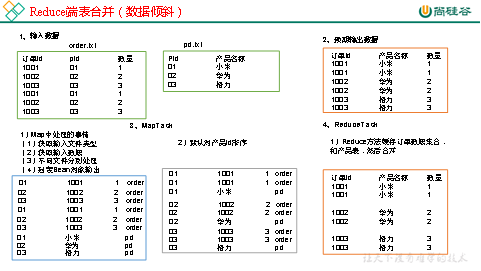
图4-20 Reduce端表合并
3.代码实现
1)创建商品和订合并后的Bean类
|
package com.atguigu.mapreduce.table; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable;
public class TableBean implements Writable {
private String order_id; // 订单id private String p_id; // 产品id private int amount; // 产品数量 private String pname; // 产品名称 private String flag; // 表的标记
public TableBean() { super(); }
public TableBean(String order_id, String p_id, int amount, String pname, String flag) {
super();
this.order_id = order_id; this.p_id = p_id; this.amount = amount; this.pname = pname; this.flag = flag; }
public String getFlag() { return flag; }
public void setFlag(String flag) { this.flag = flag; }
public String getOrder_id() { return order_id; }
public void setOrder_id(String order_id) { this.order_id = order_id; }
public String getP_id() { return p_id; }
public void setP_id(String p_id) { this.p_id = p_id; }
public int getAmount() { return amount; }
public void setAmount(int amount) { this.amount = amount; }
public String getPname() { return pname; }
public void setPname(String pname) { this.pname = pname; }
@Override public void write(DataOutput out) throws IOException { out.writeUTF(order_id); out.writeUTF(p_id); out.writeInt(amount); out.writeUTF(pname); out.writeUTF(flag); }
@Override public void readFields(DataInput in) throws IOException { this.order_id = in.readUTF(); this.p_id = in.readUTF(); this.amount = in.readInt(); this.pname = in.readUTF(); this.flag = in.readUTF(); }
@Override public String toString() { return order_id + "\t" + pname + "\t" + amount + "\t" ; } } |
2)编写TableMapper类
|
package com.atguigu.mapreduce.table; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean>{
String name; TableBean bean = new TableBean(); Text k = new Text(); @Override protected void setup(Context context) throws IOException, InterruptedException {
// 1 获取输入文件切片 FileSplit split = (FileSplit) context.getInputSplit();
// 2 获取输入文件名称 name = split.getPath().getName(); }
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取输入数据 String line = value.toString(); // 2 不同文件分别处理 if (name.startsWith("order")) {// 订单表处理
// 2.1 切割 String[] fields = line.split("\t"); // 2.2 封装bean对象 bean.setOrder_id(fields[0]); bean.setP_id(fields[1]); bean.setAmount(Integer.parseInt(fields[2])); bean.setPname(""); bean.setFlag("order"); k.set(fields[1]); }else {// 产品表处理
// 2.3 切割 String[] fields = line.split("\t"); // 2.4 封装bean对象 bean.setP_id(fields[0]); bean.setPname(fields[1]); bean.setFlag("pd"); bean.setAmount(0); bean.setOrder_id(""); k.set(fields[0]); }
// 3 写出 context.write(k, bean); } } |
3)编写TableReducer类
|
package com.atguigu.mapreduce.table; import java.io.IOException; import java.util.ArrayList; import org.apache.commons.beanutils.BeanUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> {
@Override protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {
// 1准备存储订单的集合 ArrayList<TableBean> orderBeans = new ArrayList<>(); // 2 准备bean对象 TableBean pdBean = new TableBean();
for (TableBean bean : values) {
if ("order".equals(bean.getFlag())) {// 订单表
// 拷贝传递过来的每条订单数据到集合中 TableBean orderBean = new TableBean();
try { BeanUtils.copyProperties(orderBean, bean); } catch (Exception e) { e.printStackTrace(); }
orderBeans.add(orderBean); } else {// 产品表
try { // 拷贝传递过来的产品表到内存中 BeanUtils.copyProperties(pdBean, bean); } catch (Exception e) { e.printStackTrace(); } } }
// 3 表的拼接 for(TableBean bean:orderBeans){
bean.setPname (pdBean.getPname()); // 4 数据写出去 context.write(bean, NullWritable.get()); } } } |


