尚硅谷之MySQL基础
第12章 select的5个子句
1、where条件查询
从原表中的记录中进行筛选
2、group by 分组查询
很多情况下,用户都需要进行一些汇总操作,比如统计整个公司的人数或者统计每一个部门的人数等。
聚合函数
- AVG(【DISTINCT】 expr) 返回expr的平均值
- COUNT(【DISTINCT】 expr)返回expr的非NULL值的数目
- MIN(【DISTINCT】 expr)返回expr的最小值
- MAX(【DISTINCT】 expr)返回expr的最大值
- SUM(【DISTINCT】 expr)返回expr的总和
|
#聚合函数 #AVG(【DISTINCT】 expr) 返回expr的平均值 SELECT AVG(basic_salary) FROM t_salary; #COUNT(【DISTINCT】 expr)返回expr的非NULL值的数目 #统计员工总人数 SELECT COUNT(*) FROM t_employee;#count(*)统计的是记录数 #统计员工表的员工所在部门数 SELECT COUNT(dept_id) FROM t_employee;#统计的是非NULL值 SELECT COUNT(DISTINCT dept_id) FROM t_employee;#统计的是非NULL值,并且去重 #MIN(【DISTINCT】 expr)返回expr的最小值 #查询最低基本工资值 SELECT MIN(basic_salary) FROM t_salary; #MAX(【DISTINCT】 expr)返回expr的最大值 #查询最高基本工资值 SELECT MAX(basic_salary) FROM t_salary; #查询最高基本工资与最低基本工资的差值 SELECT MAX(basic_salary)-MIN(basic_salary) FROM t_salary; #SUM(【DISTINCT】 expr)返回expr的总和 #查询基本工资总和 SELECT SUM(basic_salary) FROM t_salary; |
group by + 聚合函数
|
#group by + 聚合函数 #统计每个部门的人数 SELECT dept_id,COUNT(*) FROM t_employee GROUP BY dept_id; #统计每个部门的平均基本工资 SELECT emp.dept_id,AVG(s.basic_salary ) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id; #统计每个部门的年龄最大者 SELECT dept_id,MIN(birthday) FROM t_employee GROUP BY dept_id; #统计每个部门基本工资最高者 SELECT emp.dept_id,MAX(s.basic_salary ) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id; #统计每个部门基本工资之和 SELECT emp.dept_id,SUM(s.basic_salary ) FROM t_employee AS emp,t_salary AS s WHERE emp.eid = s.eid GROUP BY emp.dept_id; |
注意:
用count(*),count(1),谁好呢?
其实,对于myisam引擎的表,没有区别的.
这种引擎内部有一计数器在维护着行数.
Innodb的表,用count(*)直接读行数,效率很低,因为innodb真的要去数一遍.
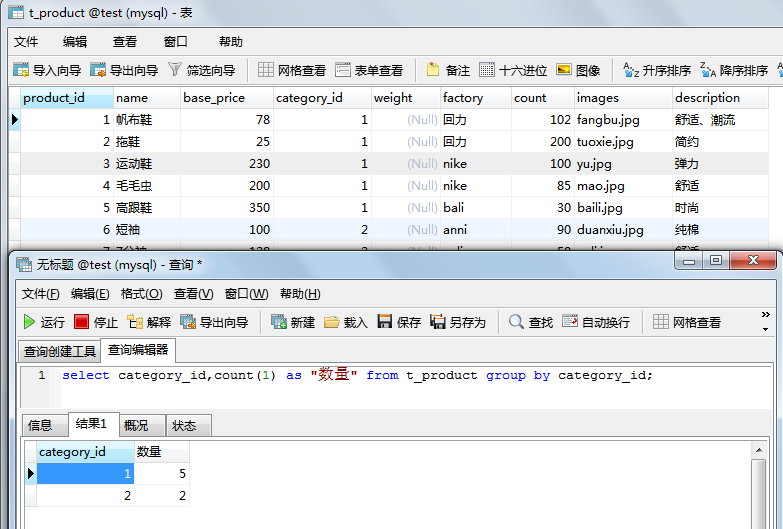
关于mysql的group by的特殊:
注意:在SELECT 列表中所有未包含在组函数中的列都应该是包含在 GROUP BY 子句中的,换句话说,SELECT列表中最好不要出现GROUP BY子句中没有的列。
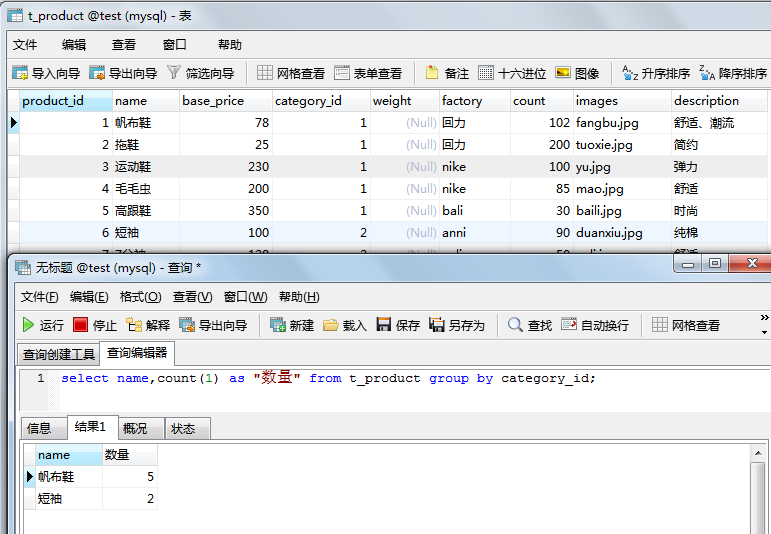
对于标准语句来说,这个语句是错误的,但是mysql可以这么干,出于可移植性和规范性,不推荐这么写。