Redis 第1章 Redis入门 第2章 Redis基本操作
第1章 Redis入门
1. 互联网项目架构演变

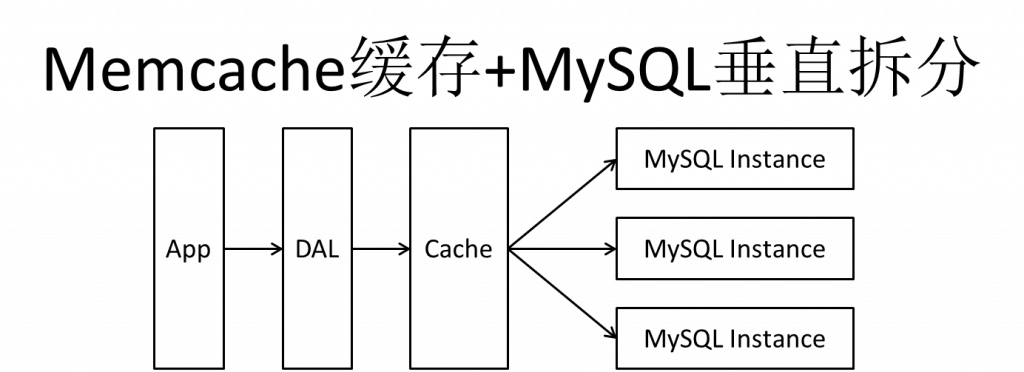
随着访问量上升,大部分使用MySQL架构的网站在数据库上都开始出现性能问题,Web程序不能再仅仅专注在功能上,同时也在追求性能。开始使用缓存技术缓解数据库压力,优化数据库的结构和索引。刚开始时比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大,文件缓存中的数据不能在多台Web服务器之间共享,大量的小文件IO也带来了比较高的IO压力。在这种情况下,Memcache就成了一款非常有效的解决方案。
Memcache作为一个独立的分布式缓存服务器,为多个Web服务器提供了一个共享的高性能缓存服务,在Memcache服务器上,又发展了根据hash算法来进行多台Memcache缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效问题。

由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了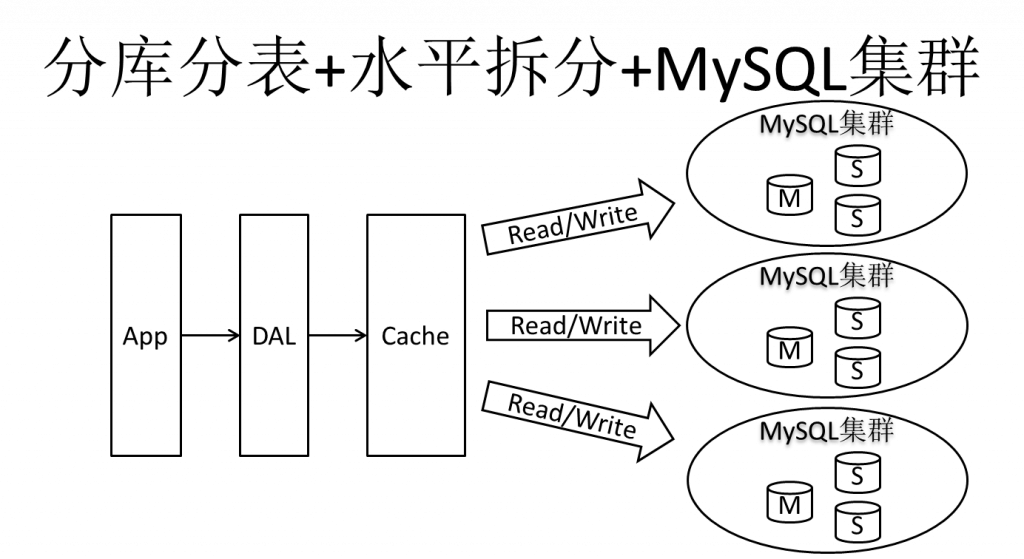
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
现在的互联网架构: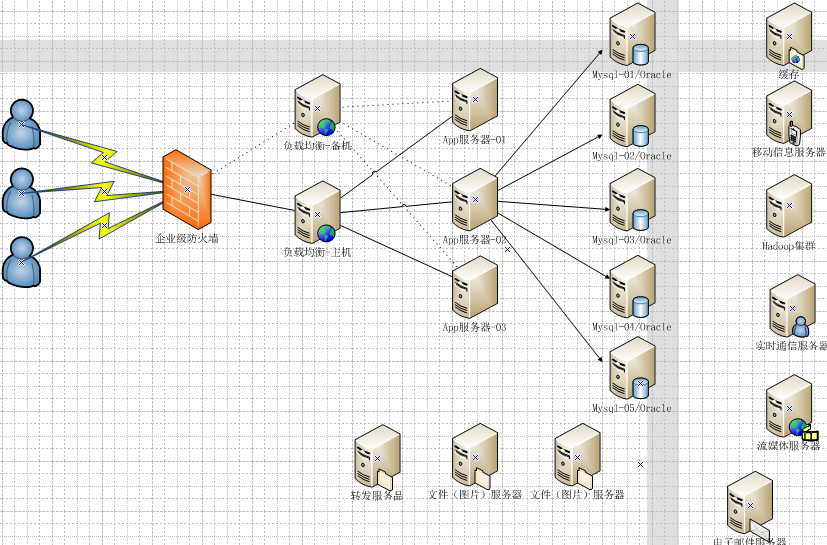
目前互联网的新要求:3V和3高
大数据时代的3V
Volume:海量,数据量极大
Variety:多样
数据类型:文本、图片、音频、视频……
终端设备:PC、移动端、嵌入式设备……
Velocity:实时
直播,金融证券……
互联网时代的3高
高可扩
不断优化现有的功能,不断开发新的功能;
高性能
不能让用户感觉到等待的时间;
高并发
同时处理并发请求的能力,如双十一的秒杀、抢购火车票;
提升硬件,优化系统,优化项目,将费时的操作进入异步处理;
2. NoSQL
不仅仅是SQL—关系型数据库的强大助力
NoSQL数据库的优势
- 易扩展
- NoSQL数据库种类繁多,但它们都有一个共通的特点:就是去除关系型数据库的“关系型”特点。数据之间无关系,这样就变得非常容易扩展,而相对应的来看:关系型数据库修改表结构非常困难。这就为项目架构设计提供了更大的扩展空间。
- 大数据量高性能
- NoSQL数据库都具有非常高的读写性能,尤其在大数据量的情况下,表现同样优秀。这得益于NoSQL数据库中数据之间没有“关系”,数据库结构简单。
- 从缓存角度来看,MySQL的Query Cache是表级别的粗粒度缓存,假设存储了100条数据,其中有一条数据修改了,整个缓存失效,效率很低。而NoSQL数据库的缓存是记录级的细粒度缓存,任何一条记录的修改都不影响其他记录,效率很高。
- 多样灵活的数据模型
- NoSQL数据库无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增减修改字段简直就是一个噩梦。
3. Redis
3.1 简介
Redis:Remote Dictionary Server(远程字典服务器)
官网:
3.2 安装
①将Redis的tar包上传到opt目录
②解压缩
③安装gcc环境
我们需要将源码编译后再安装,因此需要安装c语言的编译环境!不能直接make!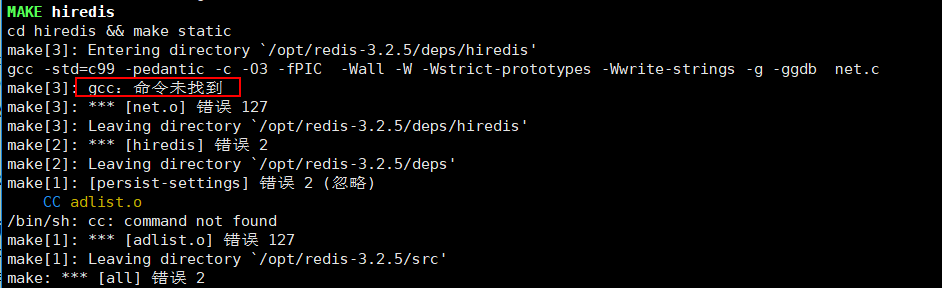
两种方式:
第一种:可以上网,yum install –y gcc-c++![]()
第二种:不能上网,确保插入了安装光盘!(CentOS6)
挂载安装光盘,然后进入Packages中,依次执行以下命令:
|
rpm -ivh mpfr-2.4.1-6.el6.x86_64.rpm |
|
rpm -ivh cpp-4.4.7-17.el6.x86_64.rpm |
|
rpm -ivh ppl-0.10.2-11.el6.x86_64.rpm |
|
rpm -ivh cloog-ppl-0.15.7-1.2.el6.x86_64.rpm |
|
rpm -ivh gcc-4.4.7-17.el6.x86_64.rpm |
不能上网,确保插入了安装光盘!(CentOS7)
挂载安装光盘,然后进入/run/media/root/CentOS 7 x86_64/Packages中
把如下安装包找出,复制到独立目录rpmgcc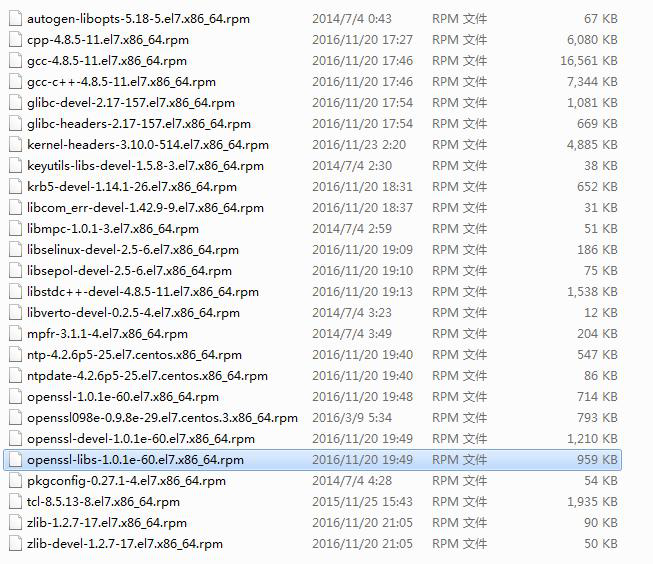
进入rpmgcc该目录运行如下命令,按照依赖关系安装
rpm -Uvh *.rpm --nodeps --force
之后查看安装是否成功:rpm –qa|grep gcc
常见错误:在没有安装gcc环境下,如果执行了make,不会成功!安装环境后,第二次make有可能报错:
Jemalloc/jemalloc.h:没有那个文件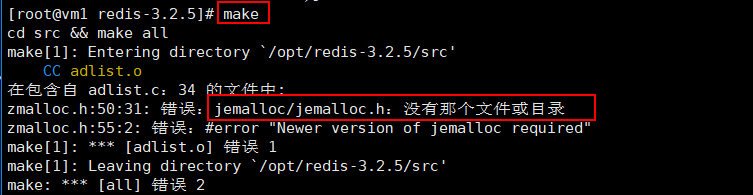
解决: 运行 make distclean之后再make
④编译,执行make命令!
⑤编译完成后,安装,执行make install命令!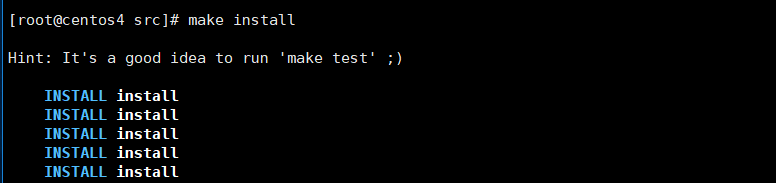
⑥文件会被安装到 /usr/local/bin目录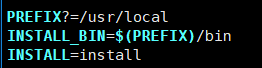
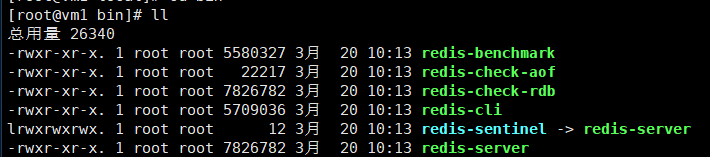
⑦可以将redis的bin目录,加入到环境变量中
|
bin目录常用命令 |
|
|
Redis-benchmark |
压力测试。标准是每秒80000次写操作,110000次读操作 (服务启动起来后执行,类似安兔兔跑分) |
|
Redis-check-aof |
修复有问题的AOF文件 |
|
Redis-check-dump |
修复有问题的dump.rdb文件 |
|
Redis-sentinel |
启动哨兵,集群使用 |
|
redis-server |
启动服务器 |
|
redis-cli |
启动客户端 |
3.3 启动
3.3.1 服务端启动
将配置文件,保留一份副本,进行启动。
命令: redis-server conf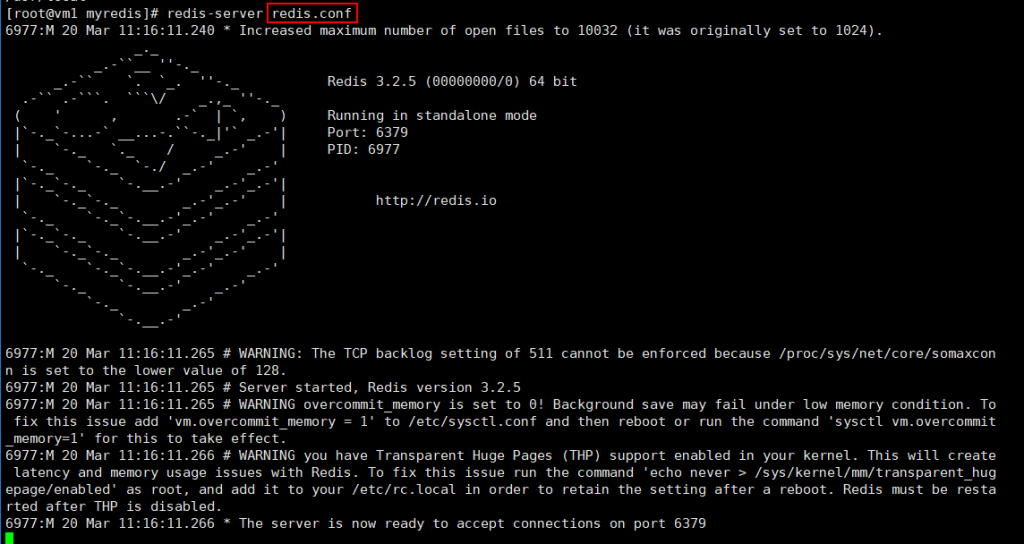
但是这样的话,发现命令窗口被占用了,很不方便。当然你可以再启动一个会话窗口。
解决:修改配置文件,改为守护进程,在后台运行
我们选择后台运行,怎么办?修改配置文件。
daemonize yes
后台启动后,查看服务: netstat –anp|grep 6379![]()

3.3.2 客户端登录
|
命令 |
说明 |
举例 |
备注 |
|
redis-cli |
启动客户端 |
redis-cli –p 端口号 连接指定的端口号 |
直接执行的话,默认端口号就是6379; |
|
ping |
测试联通 |
|
回复pong代表联通 |
|
exit |
退出客户端 |
|
|
|
redis-cli shutdown |
停止服务器 |
redis-cli -h 127.0.0.1 -p 6379 shutdown 停止指定ip指定端口号的服务器 |
redis是通过客户端发送停止服务器的命令 |
第2章 Redis基本操作
1. 数据库连接操作
|
命令 |
说明 |
举例 |
备注 |
|
select <dbid> |
切换数据库 |
select 1:切换到1号库 |
开启redis服务后,一共有16(0-15)个库,默认在0号库 |
|
flushdb |
清空当前库 |
|
|
|
dbsize |
查看数据库数据个数 |
|
|
|
flushall |
通杀全部库 |
|
|

2. key的操作
Redis中的数据以键值对(key-value)为基本存储方式,其中key都是字符串。
|
表达式 |
描述 |
|
KEYS pattern |
查询符合指定表达式的所有key,支持*,?等 |
|
TYPE key |
查看key对应值的类型 |
|
EXISTS key |
指定的key是否存在,0代表不存在,1代表存在 |
|
DEL key |
删除指定key |
|
RANDOMKEY |
在现有的KEY中随机返回一个 |
|
EXPIRE key seconds |
为键值设置过期时间,单位是秒,过期后key会被redis移除 |
|
TTL key |
查看key还有多少秒过期,-1表示永不过期,-2表示已过期 |
|
RENAME key newkey |
重命名一个key,NEWKEY不管是否是已经存在的都会执行,如果NEWKEY已经存在则会被覆盖 |
|
RENAMENX key newkey |
只有在NEWKEY不存在时能够执行成功,否则失败 |
3. 常用五大数据类型
Redis中的数据以键值对(key-value)为基本存储方式,其中key都是字符串,这里探讨数据类型都是探讨value的类型。
|
key |
value |
|
|
string |
字符串 |
|
|
list |
可以重复的集合 |
|
|
set |
不可以重复的集合 |
|
|
hash |
类似于Map<String,String> |
|
|
zset(sorted set) |
带分数的set |
|
4. String操作
String类型是Redis中最基本的类型,它是key对应的一个单一值。
二进制安全,不必担心由于编码等问题导致二进制数据变化。所以redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
Redis中一个字符串值的最大容量是512M。
|
SET key value |
添加键值对 |
|
GET key |
查询指定key的值 |
|
APPEND key value |
将给定的value追加到原值的末尾 |
|
STRLEN key |
获取值的长度 |
|
SETNX key value |
只有在 key 不存在时设置 key 的值 |
|
INCR key |
指定key的值自增1,只对数字有效 |
|
DECR key |
指定key的值自减1,只对数字有效 |
|
INCRBY key num |
自增num |
|
DECRBY key num |
自减num |
|
MSET key1 value1 key2 value2… |
同时设置多个key-value对 |
|
MGET key1 key2 |
同时获取一个或多个value |
|
MSETNX key1 value1 key2 value2 |
当key不存在时,设置多个key-value对 |
|
GETRANGE key起始索引 结束索引 |
获取指定范围的值,都是闭区间 |
|
SETRANGE key起始索引 value |
从起始位置开始覆写指定的值 |
|
GETSET key value |
以新换旧,同时获取旧值 |
|
SETEX key 过期时间 value |
设置键值的同时,设置过期时间,单位秒 |
5. list操作
在Java中list 一般是单向链表,如常见的Arraylist,只能从一侧插入。
在Redis中,list是双向链表。可以从两侧插入。
可以简单理解为两端开口的,两端都可以进出。使用一个动画来演示。
常见操作:
遍历:遍历的时候,是从左往右取值;
删除:弹栈,POP;
添加:压栈,PUSH ;
|
表达式 |
描述 |
|
KEYS pattern |
查询符合指定表达式的所有key,支持*,?等 |
|
TYPE key |
查看key对应值的类型 |
|
EXISTS key |
指定的key是否存在,0代表不存在,1代表存在 |
|
DEL key |
删除指定key |
|
RANDOMKEY |
在现有的KEY中随机返回一个 |
|
EXPIRE key seconds |
为键值设置过期时间,单位是秒,过期后key会被redis移除 |
|
TTL key |
查看key还有多少秒过期,-1表示永不过期,-2表示已过期 |
|
RENAME key newkey |
重命名一个key,NEWKEY不管是否是已经存在的都会执行,如果NEWKEY已经存在则会被覆盖 |
|
RENAMENX key newkey |
只有在NEWKEY不存在时能够执行成功,否则失败 |
3. 常用五大数据类型
Redis中的数据以键值对(key-value)为基本存储方式,其中key都是字符串,这里探讨数据类型都是探讨value的类型。
|
key |
value |
|
|
string |
字符串 |
|
|
list |
可以重复的集合 |
|
|
set |
不可以重复的集合 |
|
|
hash |
类似于Map<String,String> |
|
|
zset(sorted set) |
带分数的set |
|
4. String操作
String类型是Redis中最基本的类型,它是key对应的一个单一值。
二进制安全,不必担心由于编码等问题导致二进制数据变化。所以redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
Redis中一个字符串值的最大容量是512M。
|
SET key value |
添加键值对 |
|
GET key |
查询指定key的值 |
|
APPEND key value |
将给定的value追加到原值的末尾 |
|
STRLEN key |
获取值的长度 |
|
SETNX key value |
只有在 key 不存在时设置 key 的值 |
|
INCR key |
指定key的值自增1,只对数字有效 |
|
DECR key |
指定key的值自减1,只对数字有效 |
|
INCRBY key num |
自增num |
|
DECRBY key num |
自减num |
|
MSET key1 value1 key2 value2… |
同时设置多个key-value对 |
|
MGET key1 key2 |
同时获取一个或多个value |
|
MSETNX key1 value1 key2 value2 |
当key不存在时,设置多个key-value对 |
|
GETRANGE key起始索引 结束索引 |
获取指定范围的值,都是闭区间 |
|
SETRANGE key起始索引 value |
从起始位置开始覆写指定的值 |
|
GETSET key value |
以新换旧,同时获取旧值 |
|
SETEX key 过期时间 value |
设置键值的同时,设置过期时间,单位秒 |
5. list操作
在Java中list 一般是单向链表,如常见的Arraylist,只能从一侧插入。
在Redis中,list是双向链表。可以从两侧插入。
可以简单理解为两端开口的,两端都可以进出。使用一个动画来演示。
常见操作:
遍历:遍历的时候,是从左往右取值;
删除:弹栈,POP;
添加:压栈,PUSH ;
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
|
LPUSH/RPUSH key value1 value2… |
从左边/右边压入一个或多个值 头尾效率高,中间效率低 |
|
LPOP/RPOP key |
从左边/右边弹出一个值 值在键在,值光键亡 弹出=返回+删除 |
|
LRANGE key start stop |
查看指定区间的元素 正着数:0,1,2,3,... 倒着数:-1,-2,-3,... |
|
LINDEX key index |
按照索引下标获取元素(从左到右) |
|
LLEN key |
获取列表长度 |
|
LINSERT key BEFORE|AFTER value newvalue |
在指定value的前后插入newvalue |
|
LREM key n value |
从左边删除n个value |
|
LSET key index value |
把指定索引位置的元素替换为另一个值 |
|
LTRIM key start stop |
仅保留指定区间的数据 |
|
RPOPLPUSH key1 key2 |
从key1右边弹出一个值,左侧压入到key2 |
6. set操作
set是无序的,且是不可重复的。
|
SADD key member [member ...] |
将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。 |
|
SMEMBERS key |
取出该集合的所有值 |
|
SISMEMBER key value |
判断集合<key>是否为含有该<value>值,有返回1,没有返回0 |
|
SCARD key |
返回集合中元素的数量 |
|
SREM key member [member ...] |
从集合中删除元素 |
|
SPOP key [count] |
从集合中随机弹出count个数量的元素,count不指定就弹出1个 |
|
SRANDMEMBER key [count] |
从集合中随机返回count个数量的元素,count不指定就返回1个 |
|
SINTER key [key ...] |
将指定的集合进行“交集”操作 |
|
SINTERSTORE dest key [key ...] |
取交集,另存为一个set |
|
SUNION key [key ...] |
将指定的集合执行“并集”操作 |
|
SUNIONSTORE dest key [key ...] |
取并集,另存为set |
|
SDIFF key [key ...] |
将指定的集合执行“差集”操作 |
|
SDIFFSTORE dest key [key ...] |
取差集,另存为set |
7. hash操作
Hash数据类型的键值对中的值是“单列”的,不支持进一步的层次结构。
|
key |
field:value |
|
"k01":"v01" "k02":"v02" "k03":"v03" "k04":"v04" "k05":"v05" "k06":"v06" "k07":"v07" |
从前到后的数据对应关系
- JSON
stu:{"stu_id":10,"stu_name":"tom","stu_age":30}
- Java
public class Student {
private Integer stuId;//10
private String stuName;//"tom"
private Integer stuAge;//30
...
}
Student stu=new Student()’
stu.setStuId=10;
stu.setStuName=”tom”;
stu.setStuAge=30;
- Redis hash
|
key |
value(hash) |
|
|
stu |
stu_id |
10 |
|
stu_name |
tom |
|
|
stu_age |
30 |
|
常用操作:
|
HSET key field value |
为key中的field赋值value |
|
HMSET key field value [field value ...] |
为指定key批量设置field-value |
|
HSETNX key field value |
当指定key的field不存在时,设置其value |
|
HGETALL key |
获取指定key的所有信息(field和value) |
|
HKEYS key |
获取指定key的所有field |
|
HVALS key |
获取指定key的所有value |
|
HLEN key |
指定key的field个数 |
|
HGET key field |
从key中根据field取出value |
|
HMGET key field [field ...] |
为指定key获取多个filed的值 |
|
HEXISTS key field |
指定key是否有field |
|
HINCRBY key field increment |
为指定key的field加上增量increment |
8. zset操作
zset是一种特殊的set(sorted set),在保存value的时候,为每个value多保存了一个score信息。根据score信息,可以进行排序。
这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了
|
ZADD key [score member ...] |
添加 |
|
ZSCORE key member |
返回指定值的分数 |
|
ZRANGE key start stop [WITHSCORES] |
返回指定区间的值,可选择是否一起返回scores |
|
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] |
在分数的指定区间内返回数据,从小到大排列 |
|
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] |
在分数的指定区间内返回数据,从大到小排列 |
|
ZCARD key |
返回集合中所有的元素的数量 |
|
ZCOUNT key min max |
统计分数区间内的元素个数 |
|
ZREM key member |
删除该集合下,指定值的元素 |
|
ZRANK key member |
返回该值在集合中的排名,从0开始 |
|
ZINCRBY key increment value |
为元素的score加上增量 |


