大数据培训项目程序部署与运行
1 发布项目
编译项目:执行root项目的clean package阶段
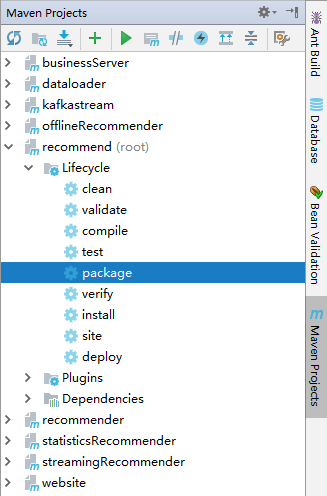
编译完成如下:
2 安装前端项目
将website-release.tar.gz解压到/var/www/html目录下,将里面的文件放在根目录,如下:
启动Apache服务器,访问http://IP:80
3 安装业务服务器
将BusinessServer.war,放到tomcat的webapp目录下,并将解压出来的文件,放到ROOT目录下:

启动Tomcat服务器。
4 Kafka配置与启动
启动Kafka
在kafka中创建两个Topic,一个为log,一个为recommender
启动kafkaStream程序,用于在log和recommender两个topic之间进行数据格式化。
|
[bigdata@linux ~]$ java -cp kafkastream.jar com.atguigu.kafkastream.Application linux:9092 linux:2181 log recommender |
5 Flume配置与启动
在flume安装目录下的conf文件夹下,创建log-kafka.properties
|
agent.sources = exectail agent.channels = memoryChannel agent.sinks = kafkasink
# For each one of the sources, the type is defined agent.sources.exectail.type = exec agent.sources.exectail.command = tail -f /home/bigdata/cluster/apache-tomcat-8.5.23/logs/catalina.out agent.sources.exectail.interceptors=i1 agent.sources.exectail.interceptors.i1.type=regex_filter agent.sources.exectail.interceptors.i1.regex=.+MOVIE_RATING_PREFIX.+ # The channel can be defined as follows. agent.sources.exectail.channels = memoryChannel
# Each sink's type must be defined agent.sinks.kafkasink.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.kafkasink.kafka.topic = log agent.sinks.kafkasink.kafka.bootstrap.servers = linux:9092 agent.sinks.kafkasink.kafka.producer.acks = 1 agent.sinks.kafkasink.kafka.flumeBatchSize = 20
#Specify the channel the sink should use agent.sinks.kafkasink.channel = memoryChannel
# Each channel's type is defined. agent.channels.memoryChannel.type = memory
# Other config values specific to each type of channel(sink or source) # can be defined as well # In this case, it specifies the capacity of the memory channel agent.channels.memoryChannel.capacity = 10000 |
启动flume
|
[bigdata@linux apache-flume-1.7.0-kafka]$ bin/flume-ng agent -c ./conf/ -f ./conf/log-kafka.properties -n agent |
6 部署流式计算服务
提交SparkStreaming程序:
|
[bigdata@linux spark-2.1.1-bin-hadoop2.7]$ bin/spark-submit --class com.atguigu.streamingRecommender.StreamingRecommender streamingRecommender-1.0-SNAPSHOT.jar |
7 Azkaban调度离线算法
创建调度项目
创建两个job文件如下:
Azkaban-stat.job:
|
type=command command=/home/bigdata/cluster/spark-2.1.1-bin-hadoop2.7/bin/spark-submit --class com.atguigu.offline.RecommenderTrainerApp offlineRecommender-1.0-SNAPSHOT.jar |
Azkaban-offline.job:
|
type=command command=/home/bigdata/cluster/spark-2.1.1-bin-hadoop2.7/bin/spark-submit --class com.atguigu.statisticsRecommender.StatisticsApp statisticsRecommender-1.0-SNAPSHOT.jar |
将Job文件打成ZIP包上传到azkaban:
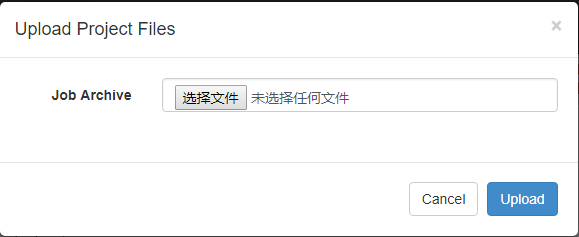
如下:
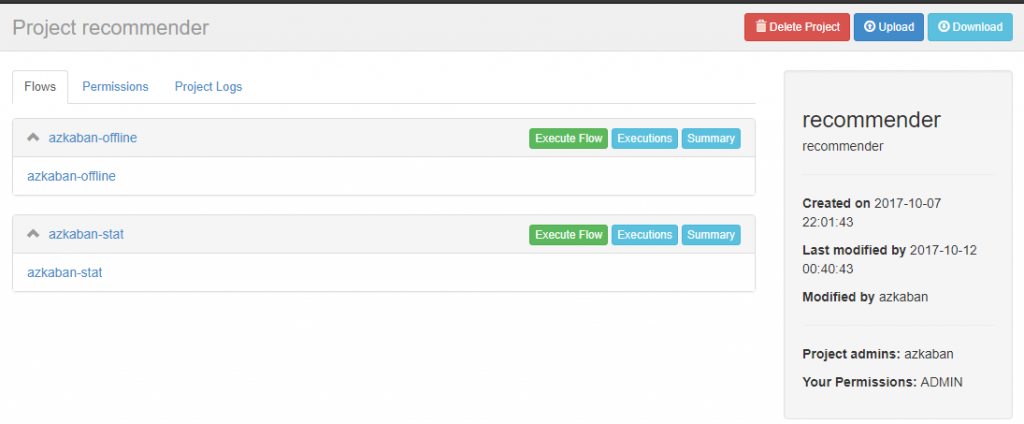
分别为每一个任务定义指定的时间,即可:
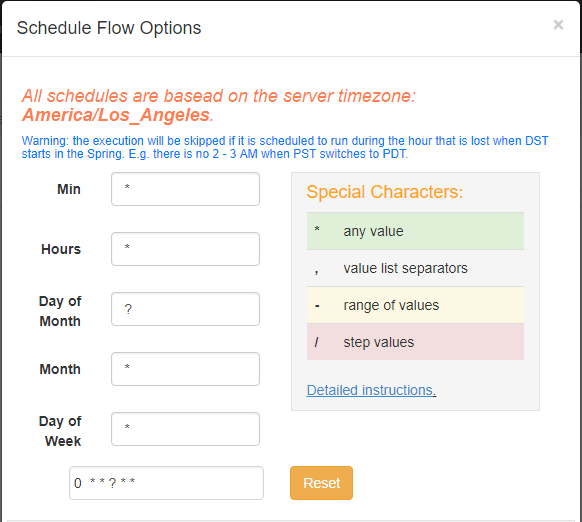
定义完成之后,点击Scheduler即可。
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。