大数据培训技术基于用户的协同过滤
基于近邻的推荐
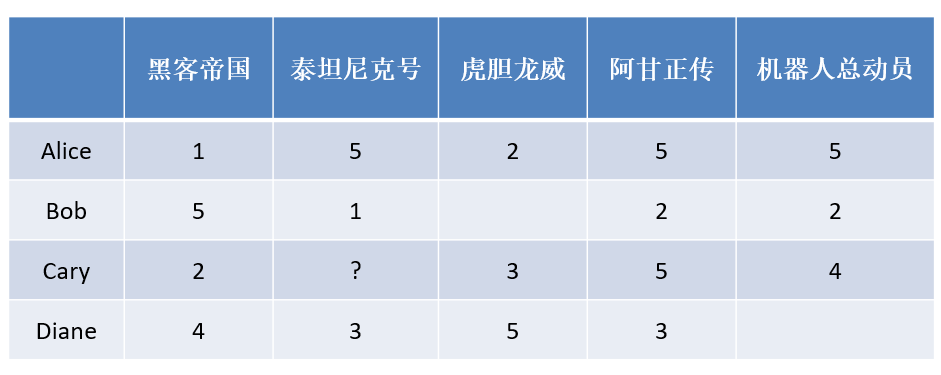
1、基于近邻的推荐系统根据的是相同“口碑”准则
2、是否应该给Cary推荐《泰坦尼克号》?
基于用户的协同过滤
基于用户的协同过滤(User-CF)
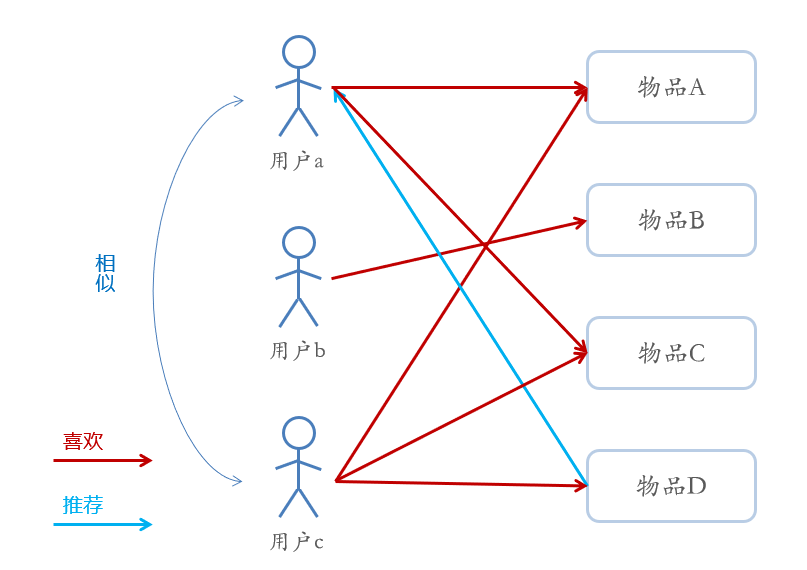
1、基于用户的协同过滤推荐的基本原理是,根据所有用户对物品的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,并推荐近邻所偏好的物品
2、在一般的应用中是采用计算“K- 近邻”的算法;基于这 K 个邻居的历史偏好信息,为当前用户进行推荐
3、User-CF 和基于人口统计学的推荐机制
–两者都是计算用户的相似度,并基于相似的“邻居”用户群计算推荐
–它们所不同的是如何计算用户的相似度:基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。